
Security-Chaos-Engineering : Ansätze zur kontinuierlichen Überprüfung der CloudSicherheitslage
Will man effektiv gegen Cyberangriffe auf Cloud-native Infrastrukturen vorgehen, muss man deren Resilienz erhöhen und zugehörige Sicherheitskontrollen dynamisieren – stetig, kontinuierlich, ohne Pause, denn schließlich entwickeln auch Cyberkriminelle ihre Angriffsvektoren beständig weiter. Das Security-Chaos-Engineering versucht, an dieser Stelle anzusetzen und eine Sicherheitsbewertung quasi in Echtzeit zu verwirklichen.
Von Kennedy Torkura, Berlin
Cloud-native Infrastrukturen sind häufig zwar von langer Hand geplant, erweisen sich in der Praxis aber meist als ziemlich unsicher. Zwar gibt es präventiv einsetzbare Lösungen, mit denen sich die Effektivität von Sicherheitskontrollen überprüfen lässt und mit denen man Schwachstellen in Cloud-nativen Infrastrukturen aufspüren kann, doch diese reichen nicht aus: Denn sie sind für statische On-Premises-, nicht jedoch für dynamische Cloud-Infrastrukturen konzipiert.
Gerade diese Dynamik aber muss berücksichtigt werden! Denn wenn sich eine Cloud-native Infrastruktur nach einer Überprüfung durch Sicherheitskontrollen weiterentwickelt, büßen die Ergebnisse dieser Prüfung an Wert ein oder verlieren ihn gleich ganz. Ein relativ neuer Ansatz verspricht hier Abhilfe: Security-Chaos-Engineering. Diese Methode ermöglicht eine objektive Bewertung der eigenen Sicherheitskontrollen – quasi in Echtzeit.
Dark Debt
Als Haupteinfallstore gelten auch in Cloud-nativen Infrastrukturen Fehlkonfigurationen, Schwachstellen und schwache Zugangskontrollmechanismen – sowie teilweise oder sogar gänzlich falsch aufgestellte und ausgerichtete Sicherheitskontrollen. Cloud-native Infrastrukturen sind in aller Regel überaus umfangreich, komplex und dynamisch – entsprechend schwierig gestalten sich die Konzeption, Implementierung und Nachjustierung einer wirklich umfassenden Sicherheitsarchitektur.
Vorausschauende Planungen, klassische Simulationen und Tests helfen nur bedingt: Zu fluide sind Cloud-Infrastrukturen, als dass derart statische Lösungen bei ihnen effektiv greifen könnten. Erschwerend kommt hinzu, dass Cloud-native Systeme – mit wachsendem Umfang und zunehmender Komplexität – dazu neigen, zu einem Schmelztiegel für sogenanntes Dark Debt zu werden.
Will man effektiv gegen Cyberangriffe auf Cloud-native Infrastrukturen vorgehen, muss man deren Resilienz erhöhen und zugehörige Sicherheitskontrollen dynamisieren – stetig, kontinuierlich, ohne Pause, denn schließlich entwickeln auch Cyberkriminelle ihre Angriffsvektoren beständig weiter. Das Security-Chaos-Engineering versucht, an dieser Stelle anzusetzen und eine Sicherheitsbewertung quasi in Echtzeit zu verwirklichen.
Bei Dark Debt handelt es sich um Schwachstellen, die erst mit einer gewissen Komplexität, also nach Zunahme des Zusammenspiels verschiedener Hard-, Firm- und Software auftreten – vorrangig passiert das in Cloud-nativen Infrastrukturen. Da deren IT-Assets häufig unterschiedlich alt sind, während ihrer Entwicklung also möglicherweise abweichende Vorgaben und Richtlinien galten, harmonieren diese längst nicht immer miteinander. So können bestimmte Interaktionen unvorhergesehene Reaktionen – bis hin zu einem Totalausfall der gesamten Infrastruktur – nach sich ziehen.
Sich hiergegen zu schützen und die Verfügbarkeit der Cloud-nativen Infrastruktur sicherzustellen, ist schwer: Denn bis zum Eintreten einer Reaktion bleibt Dark Debt unsichtbar. Es kann auf vier Ebenen auftreten: auf der Infrastruktur-, Plattform-, Anwendungs- sowie der Personen-, Praktiken- und Prozess-Ebene. Um die Verfügbarkeit einer Infrastruktur effektiv sicherzustellen, sind deshalb alle vier Ebenen kontinuierlich und umfassend zu überwachen.
Chaos-Engineering
Chaos-Engineering hilft dabei, Dark Debt aufzuspüren, bevor es sich zu einem kritischen Problem für Cloud-native Infrastrukturen auswächst. Anwender können mithilfe dieser Methode effektiv ermitteln, ob und wo in ihrer Infrastruktur, ihren Plattformen, ihren Anwendungen, bei Personen, Richtlinien und Praktiken etwaige Dark-Debt-Schwachstellen lauern – und diese beheben, bevor sie das Gesamtgefüge gefährden. Hierzu werden in einer Simulation der Infrastruktur zuvor definierte realistische Fehlerszenarien durchgespielt, um zu ermitteln, ob das System ihnen standhält.
Traditionell erfolgt Chaos-Engineering manuell durch Teams, die von einem Chaos-Engineer unterstützt und angeleitet wurden. Eine manuelle Umsetzung ist jedoch mit erheblichem Arbeitsaufwand verbunden, was Frequenz, Art und Umfang der Verfügbarkeitstests stark einschränkt.
Mittlerweile steht allerdings auch eine ganze Reihe moderner Chaos-Engineering-Lösungen als Software as a Service (SaaS) bereit, die es Anwendern ermöglicht, solche Experimente automatisiert ablaufen zu lassen. Der große Vorteil: In puncto Komplexität und Umfang sind sie damit praktisch unbegrenzt skalierbar. Sie lassen sich auf allen Ebenen der Infrastruktur (Anwendungen, Cloud-Umgebungen, Kubernetes-Clustern usw.) in Echtzeit umsetzen. Das ganze soziotechnologische System kann so in den Blick genommen werden: Dark Debt lässt sich effektiv und effizient reduzieren, Downtime minimieren und die Verfügbarkeit der gesamten Infrastruktur optimieren. Verfügbarkeits- und Leistungsprobleme – ob nun natürlich oder künstlich, zum Beispiel durch menschliches Fehlverhalten, herbeigeführt – können so in Quantität wie Qualität deutlich zurückgefahren werden.
Security-Chaos-Engineering
Um vollumfänglich für Informationssicherheit in der Cloud zu sorgen, genügt es natürlich nicht, allein die Verfügbarkeit zu gewährleisten – auch Integrität und Vertraulichkeit sind sicherzustellen. Und genau hier kommt nun Security-Chaos-Engineering (SCE) ins Spiel: eine Methode zur Analyse der Wirksamkeit bestehender Sicherheitskontrollen, die auf dem Prinzip des Chaos-Engineering beruht.
Durch proaktives Experimentieren mit geplanten, künstlich herbeigeführten Angriffen lässt sich mit SCE das reale Verhalten der Sicherheitskontrollen objektiv dahingehend bewerten, ob sie einen Angriff, wie erhofft, abwehren können – oder eben nicht. Die Reaktion der Sicherheitskontrollen wird beobachtet, analysiert und ausgewertet. Auf Basis dieser Auswertung lassen sich dann Empfehlungen aussprechen und Änderungen an den Einstellungen der Sicherheitskontrollen vornehmen.
Das Besondere daran: Ein Angriff wird als Hypothese formuliert. Deren Überprüfung erfolgt dann durch das Sammeln von Beweisen – die Reaktion der Kontrollen. Anders als bei manchen anderen Analyse- oder Bewertungsmethoden handelt es sich deshalb hier um einen objektiven, faktenbasierten Analyseprozess – und nicht um bloße Vermutungen und subjektive Annahmen.
Mit SCE lassen sich Angriffstypen und -szenarien, zum Beispiel ein Ransomware-, UnauthorizedAccess-to-AWS-Lambda-Functions- oder Manipulation-of-AWS-SecurityGroups-Angriffe, in einem Experiment, das der Infrastruktur in Echtzeit nachempfunden ist, realistisch durchspielen. Auf diesem Wege kann man nicht nur effektiv und effizient vermutete Lücken in den Sicherheitskontrollen aufspüren, sondern auch solche, an die das IT-Sicherheitsteam vielleicht noch gar nicht gedacht hat.
Von Sicherheitskontrollen über die Anomalie-Aufspürung, Vorfallsreaktion und Systemwiederherstellung bis hin zur Einhaltung von Compliance-Vorgaben lassen sich dabei alle Sicherheitslösungen effektiv und effizient evaluieren, im Hinblick auf ihre Effektivität verifizieren und dann – bei Bedarf – optimieren.
Vorzüge von SCE
Traditionell setzen Red, Blue und Purple Teams der IT-Sicherheit zum Aufspüren von Sicherheitslücken und Schwachstellen auf Methoden wie Fuzzing und Penetration-Testing. Doch solche Methoden erfordern in der Umsetzung viel manuellen Arbeitsaufwand und Zeit, was eine umfassende Analyse der Sicherheitskontrollen erschwert, eine kontinuierliche Prüfung sogar praktisch unmöglich macht. Hinzu kommt: Fuzzing kann lediglich Anwendungen testen und dies auch nur in Entwicklungs-, nicht aber in Produktionsumgebungen. Mit Penetrationstests lässt sich zwar schon deutlich mehr erreichen, doch werden diese in aller Regel als BlackBox-Test durchgeführt: Die Angriffe erfolgen so, als ob die Angreifer nur sehr wenig oder gar nichts über die zu attackierende Infrastruktur und ihre Sicherheitskontrollen wüssten.

Abbildung 1: Angriffspfade können in Cloudnativer Infrastruktur über mehrere Abstraktionsschichten ablaufen, die alle geschützt werden müssen – diese Komplexität erschwert manuelle Prüfungen enorm.
Chaos-Engineering lässt sich hingegen in allen Umgebungen realisieren, muss nicht auf einzelne Anwendungen beschränkt bleiben und kann als White-Box-Test durchgeführt werden. Das Experiment verläuft also so, als ob beim Angreifer bereits ein tieferes Verständnis der Infrastruktur und Sicherheitskontrollen des Opfers vorhanden wäre. Tabelle 1 führt weitere Vergleiche der verschiedenen Methoden auf.
Von den Vorzügen des SCE können neben IT-Sicherheits-Teams auch IT-Sicherheits-Beauftragte profitieren – denn SCE:
- senkt das Risiko erfolgreicher Cyberangriffe – Sicherheitslücken und Schwachstellen können rechtzeitig entdeckt und behoben werden.
- stärkt das Vertrauen der IT-Sicherheitsteams in ihre Sicherheitskontrollen – dank realer Angriffstypen und -szenarien auf die tatsächliche Infrastruktur können sie sich eine beweiskräftige Vorstellung von der Resilienz ihres Systems machen.
- liefert IT-Sicherheitsbeauftragten beweiskräftige Aussagen zur Effektivität aller bereits implementierten Sicherheitstools und hilft ihnen so dabei, deren „Return of Invest“ (ROI) nicht mehr subjektiv, sondern objektiv zu bewerten.
- erleichtert Security-Engineers die Durchführung von Sicherheitsübungen – zum Beispiel zur Optimierung der Reaktion einzelner Abteilungen oder auch der gesamten Belegschaft auf Cyberangriffe oder der Wiederherstellung der Infrastruktur.
- hilft IT-Sicherheitsbeauftragten bei der Einordnung der Sicherheitskontrollen in ein Reifegradmodell, was eine objektivere, nachvollziehbarere Planung ihrer Optimierung ermöglicht.
- unterstützt IT-Sicherheitsbeauftragte bei der Implementierung und Umsetzung einer umfassenden Zero-Trust-Architecture (ZTA) – auch und gerade in der Cloud kann es bei deren Einrichtung leicht zu Fehlkonfigurationen mit gravierenden Folgen kommen. Die Effizienz und den Sicherheits-ROI von ZTA-Implementierungen zu prüfen, ist dementsprechend eine wichtige Aufgabe, die SCE bedeutend erleichtern kann.
Realisierung von SCE
Um SCE-Experimente effektiv durchzuführen, gibt es (wie so oft) zwei Möglichkeiten: Entweder baut man ein internes Expertenteam auf oder nimmt Dienste eines externen Plattform-Anbieters in Anspruch.
Interne Umsetzung: Entscheidet man sich für Ersteres, muss Um ein Team für das Security-Chaos-Engineering zusammenzustellen, sollte man zunächst ein Team von Senior Engineers auswählen. Jedes Teammitglied sollte neben vier bis fünf Jahren Arbeitserfahrung zumindest über grundlegende Kenntnisse im Bereich des Security-Chaos-Engineering verfügen. Solch ein Team kann in der Regel drei bis fünf einmalige Angriffe pro Woche entwickeln und durchführen. Allerdings muss man einige Zeit einplanen, bis die Teammitglieder sich eingearbeitet und mit der Infrastruktur vertraut gemacht haben.
SaaS-Plattform: Kosten und Arbeitsaufwand bei der Inanspruchnahme einer SaaS-SCE-Plattform fallen oft deutlich niedriger aus. Diese sollte sich bereits von einem Security-Engineer problemlos bedienen lassen. Nach der Einarbeitung dauert die Einrichtung eines Angriffstyps oder eines Angriffsszenarios oft nur noch wenige Minuten. Und Angriffe können dank tiefer Integration in die Cloud und entsprechender Automatisierung kontinuierlich ablaufen, sollten sich also – einmal eingerichtet – automatisiert umsetzen lassen. SCE-Plattformen stellen Anwendern eine Vielzahl unterschiedlicher Angriffstypen zur Verfügung, die auch als Bausteine für die Konstruktion komplexer Angriffsszenarien nutzbar sind. Der Pool entsprechender Angriffstypen und -szenarien sollte dazu vom Anbieter ständig erweitert werden, sodass sich der Anwender selbst nicht um Updates kümmern muss. Gute SaaS-Plattformen sollten zudem auf Grundlage des Risikoprofils einer Umgebung auch Empfehlungen für die Art der durchzuführenden „Angriffe“ abgeben können sowie Metriken zur Cyber-Resilienz bereitstellen, um die Entwicklung der Widerstandsfähigkeit einer Cloud-nativen Infrastruktur besser nachvollziehbar zu machen.

Tabelle 1: Fuzzing, Penetration-Testing und Security-ChaosEngineering (SCE) im Vergleich
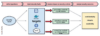
Abbildung 2: Typischer Arbeitsprozess zum SecurityQuelle: Resility Chaos-Engineering
Schritt für Schritt zur Anwendung von SCE
Um mittels SCE effektiv und effizient Schwachstellen und Sicherheitslücken aufzudecken und zu beheben, sollte eine Umsetzung stets in den folgenden vier Schritten erfolgen (vgl. Abb. 2):
- Planung: Planen Sie SCE-Angriffsexperimente auf der Grundlage Ihrer Probleme und Anwendungsfälle. Konstruieren Sie Ihre Hypothese entweder auf der Grundlage früherer Experimente oder neuer Erkenntnisse und Gedanken.
- Ausführung: Führen Sie die Experimente regelmäßig nach einem klar festgelegten Zeitplan durch – zunächst in der Entwicklungs-, dann auch in der Produktionsumgebung.
- Monitoring: Beobachten Sie die Experimente, um aus dem Verhalten des getesteten Systems zu lernen – dokumentieren Sie das Verhalten des Systems und sammeln Sie Beweise.
- Analyse: Analysieren Sie das Systemverhalten und die Beweise ausführlich und lassen Sie die Ergebnisse in die nächsten Versuchsreihen einfließen.
Des Weiteren sollte man bei der Umsetzung SCE-Experimente stets primär in einer Entwicklungsumgebung ausführen und nur bei Bedarf, um noch aussagekräftigere Werte zu erzielen, in die Produktionsumgebung wechseln, um das Risiko etwaiger Ausfallzeiten zu minimieren. Außerdem sollten alle Beteiligten im Voraus über die Tests informiert werden, um böse Überraschungen zu vermeiden. Die Experimente sollten so häufig wie möglich wiederholt werden, da jede Änderung in der Cloud die vorherige Sicherheitsanalyse potenziell ungültig macht oder ihre Aussagekraft doch zumindest mindert. Natürlich sollten festgestellte Sicherheitsprobleme auch nach jedem Versuch behoben werden.
Fazit
Eine umfassende Informationssicherheit für Cloud-native Infrastrukturen, die sowohl Entwicklungs- als auch Produktionsumgebungen abdeckt, kann von der Security-Chaos-Engineering-Methode erheblich profitieren. Die Methode erscheint teils sogar alternativlos, denn anders wird sich eine effektive Evaluierung der Sicherheitskontrollen einer komplexen Cloud-nativen Infrastruktur kaum noch verwirklichen lassen – schon gar nicht in Echtzeit.
Mittels Security-Chaos-Engineering lässt sich objektiv prüfen, ob und wie wirksam bestehende Sicherheitstools Attacken gegen die Vertraulichkeit, Integrität und Verfügbarkeit einer Cloud-nativen Infrastruktur verhindern, aufdecken und beheben können. Ähnlich wie das Chaos-Engineering die Widerstandsfähigkeit eines Systems gegen Verfügbarkeitsverletzungen erhöht, optimiert Security-Chaos-Engineering dessen Resilienz hinsichtlich Verletzungen der Integrität und Vertraulichkeit (und damit auch der Verfügbarkeit). Die Analyseergebnisse liefern einen Pool aus objektivem Wissen über die realen Fähigkeiten der eigenen Sicherheitsarchitektur, der sich anschließend für eine proaktive und iterative Sicherheitshärtung nutzen lässt.
Kennedy Torkura ist Co-Founder und CTO der Resility GmbH.