
Bestandsaufnahme Risikomanagement (1) : Problemzonen und Lösungsansätze
Heute übliche Vorgehensweisen im IT-Risikomanagement haben deutliche Schwächen, mahnt unser Autor und ergründet ausführlich Probleme und Lösungsansätze aus der Perspektive des Praktikers. Der erste Teil behandelt erkannte Defizite und leitet über eine Begriffsdiskussion hin zu einem empfehlenswerten Verfahren der Risikoidentifikation.
Von Bastian Angerstein, Besigheim
Gängige Ansätze der Risikoidentifikation im Risikomanagement der IT – beispielsweise ISO/IEC 27005:2011, DIN ISO 31000:2017 oder BSI 200-3 – bergen ebenso ernst zu nehmende wie fundamentale Schwächen, die eine Gefährdung für den Unternehmenserfolg darstellen können. Dieser Artikel will solche Probleme offenlegen und mögliche Lösungsansätze für eine bessere Risikoidentifikation, -analyse und -bewertung sowie höhere Transparenz auf Basis erprobter Vorgehensweisen aus dem Bankenumfeld (MaRisk [1]) und dem Qualitätsmanagement (FME[C]A [2]) aufzeigen.
Wesentliche Schwächen
Neben Schwachpunkten der Risikoidentifikation im heute üblichen IT-Risikomanagement sollen hier zunächst auch mögliche Folgen und typische Szenarien dargestellt werden.
Vernachlässigung unterstützender Werte
Das klassische Risikomanagement in der IT kennt zwei Wertegruppen: Primäre Werte stellen im Sinne dieser Managementsysteme bestimmte schützenswerte Eigenschaften von Informationen dar, wogegen als unterstützende Werte Komponenten von der IT-Hardware bis hin zum Gebäude gelten.
Diese Aufstellung führt dazu, dass sich ein Risikomanagementsystem häufig stark auf die Information und ihre Klassifikation fokussiert. Auch unterstützende Werte stellen jedoch in der Regel einen beträchtlichen Wert dar, der sich aus Investitionen zur Beschaffung der Komponente und zur Herstellung des Zielzustands zusammensetzt (u. a. Arbeitsaufwand für Planung, Beschaffung, Aufbau, Konfiguration etc.). Anders als ein monetärer Wert von Information lässt sich der Wert eines solchen unterstützenden Assets buchhalterisch relativ einfach und präzise ermitteln.
Unterstützende Werte müssen im Sicherheitsmanagement in der Informationstechnik also zumindest aus zweierlei Perspektiven betrachtet werden: zum einen aus dem Blickwinkel ihres unmittelbaren (z. B. buchhalterischen) Wertes, zum anderen aus der Perspektive des Wertes der Information, die damit beispielsweise verarbeitet, gelagert, erstellt oder transportiert wird. Weitere Perspektiven stellen etwa betriebswirtschaftliche Chancen oder eine wertunabhängige Toxizität von Daten dar.
Unkenntnis zentraler Werte
Es genügt jedenfalls nicht, den Blick alleine auf Informationen oder Hard- und Softwarekomponenten zu richten. Wichtiger ist es, zentrale Werte zu identifizieren: Das sind sowohl Eigenschaften von Informationen als auch physische Werte, die für den betriebswirtschaftlichen Erfolg eines Unternehmens oder einer Organisation eine hohe Kritikalität innehaben – beispielsweise Werte, deren Verlust, Beschädigung oder Korruption einen nicht zu vernachlässigenden Schaden darstellt (bzw. nach sich zieht) oder deren Exposition gegenüber Risiken für den betriebswirtschaftlichen Erfolg zwingend notwendig ist. Solche Werte korrekt zu identifizieren, ist ohne Kontext (Zusammenhänge, Abhängigkeiten und Konsequenzen) meist schwierig und unzuverlässig.
Komponentenzentriertes Risikomanagement
Das vom BSI gewählte Vorgehen ist stark komponentenzentriert: Weist eine Komponente diese oder jene Merkmale auf oder nicht auf, genügt sie dem Schutzbedarf. Komponente für Komponente wird dabei betrachtet – vom USB-Stick über den Netzwerkdrucker zur Enterprise-Firewall. Dieses Vorgehen generiert schon für normalen Schutzbedarf erheblichen Aufwand. Auch andere Vorgehensweisen wie die aus dem Qualitätsmanagement kommende „Failure Mode and Effects Analysis“ (FMEA, vgl. S. 51), der Sicherheitsstandard der Kreditkartenwirtschaft (PCI-DSS) oder das NIST Cybersecurity Framework (www.nist.gor/cyberframework) wählen diesen Weg.
Analysiert man eine Komponente für sich allein, werden Bedrohungen und Gefahren, denen sie im Anwendungsfall ausgesetzt ist, sowie die Risiken und die Folgen (Konsequenzen) eines Risikoeintritts nicht oder nur unspezifisch betrachtet. Am Beispiel Auto wird deutlich, wie realitätsfern etwa eine Betrachtung von Alterung, Diebstahl, Investitionsverlusten et cetera ohne Berücksichtigung des Anwendungsfalls „Individualverkehr“ ist. Die Folgen eines solchen Vorgehens sind lange Listen möglicher Gefahren und damit verbundener mutmaßlicher Risiken, die in der Realität allerdings vielfach kaum bis keine Relevanz haben – Risiken, die sich durch Abhängigkeiten und das Zusammenspiel von Komponenten im Anwendungsfall ergeben, werden unvollständig oder gar nicht erfasst.
Die Autoren des „Common Vulnerability Scoring System“ (CVSS) haben erkannt, dass die Bedeutung technischer Schwachstellen von der individuellen Umgebung des betroffenen Wertes abhängt. Sie führten daraufhin das „Environmental Scoring“ ein, eine Methodik zur umgebungsbezogenen Bewertung von Schwachstellen – und erkannten, dass Informationen in diesem Kontext nicht direkt, sondern nur über Eigenschaften von Software geschädigt werden. Die logische Schlussfolgerung, dass neben der rein technischen Umgebung auch die Art und Weise der Nutzung eines unterstützenden Wertes (wie Software) einen ganz erheblichen Einfluss auf das Risiko hat, dem unterstützende und primäre Werte ausgesetzt sind, blieb CVSSv3 uns indessen schuldig.
Aus Sicht des Autors löst das Vorgehen des NIST „Guide for Conducting Risk Assessments“ (NIST SP 800-30 [3]) diese Problematik am vollständigsten: Kapitel 2.4 „Application of Risk Assessments“ beschreibt ein dreistufiges Modell zur Beurteilung von Risiken, das den Betrachtungsraum in die drei horizontal gegliederten Ebenen „Organisation“, „Mission“ und „Informationssysteme“ unterteilt.
Delphi-Methode – Brainstorming – Maximalprinzip
Die in der Literatur häufig genannten und in der Praxis verbreiteten Methoden zur Erkennung von Schwachstellen und den damit verbundenen (vermeintlichen) Risiken können in der Regel kaum als präzise oder wissenschaftlich bezeichnet werden – sie lassen sich am ehesten als Methoden zur Erhebung eines „Bauchgefühls“ beschreiben. Das lässt sich leicht anhand der mangelnden Reproduzierbarkeit der Arbeitsergebnisse erkennen: Ein wissenschaftliches Vorgehen sollte bei wiederholter Anwendung identische und nachvollziehbare Resultate erzielen, was bei der Delphi-Methode und einem Brainstorming nicht gegeben ist. Sicher kann man diese Methoden nutzen, um kleinere Lücken zu schließen – sie aber als Methoden zur Erstellung von Basisdaten heranzuziehen, ist fatal.
Ein weiteres Thema ist die Anwendung des Maximalprinzips für eine Risikobewertung bei unzureichender Datenlage, wobei der größtmögliche Schadensfall angenommen wird – dieses Vorgehen ist auch Bestandteil der FMEA-Methode. Eine Adaption in den Bereich Informationssicherheit ist möglich, wird jedoch oft nicht korrekt durchgeführt. Der größtmögliche Schadensfall ist nicht die Folge des Eintritts eines Gefahrenpotenzials eines Ereignisses, sondern die Summe aller möglichen Schadensereignisse dieses Ereignisses. In Bezug auf Werte der Informationssicherheit werden zumeist die drei Dimensionen Verfügbarkeit, Integrität und Vertraulichkeit genannt. Die Auswirkung mehrerer hieraus resultierender Gefahren kann durch ein einzelnes Ereignis ausgelöst werden – zum Beispiel können Daten durch einen Trojaner zunächst gestohlen (Vertraulichkeit), anschließend der ursprüngliche Datenbestand manipuliert oder vernichtet werden (Integrität bzw. Verfügbarkeit).
Das Maximalprinzip in eindimensionalen Risikosystemen wie bei der Safety („Leib und Leben“) anzuwenden, ist korrekt und aus ethischer Sicht geboten – in den mehrdimensionalen Risikosystemen der Informationssicherheit ist jedoch zu beachten, dass Ereignisse Mehrfachschäden auslösen können. Die Annäherung an die Eintrittswahrscheinlichkeit von Mehrfachschadensereignissen ist mathematisch über die Wahrscheinlichkeit oder eine Monte-Carlo-Simulation möglich – beide Wege kommen zu ähnlichen Ergebnissen und zeigen, dass die Wahrscheinlichkeit für signifikante Mehrfachschäden etwa bei 4–6 % liegt.
Wissenschaftlich fehlerhafte Methoden
Das am häufigsten gelebte Vorgehen, ein semi-quantitativer Ansatz zur Erhebung eines Risikowerts als Produkt aus Schwere der Folgen und Häufigkeit/Wahrscheinlichkeit des Auftretens für die Dimensionen Verfügbarkeit, Vertraulichkeit und Integrität eines Ereignisses, ist bereits im Ansatz fehlerhaft (Stichwort Ordinalskala“) – doch dazu später mehr.
Domänen von Ursachen und Wirkung
Unternehmen und andere Institutionen weisen heute praktisch immer eine organisatorische Trennung zwischen IT, Produktionsbereichen und Management auf. Dies führt dazu, dass IT-Risiken von Kaufleuten oder kaufmännische Risiken durch IT-Administratoren bewertet werden. Dies kann aus zweierlei Gründen nicht funktionieren: IT-Experten sind zwar gut darin, IT-Risiken zu erkennen, können jedoch unmöglich die kaufmännische Bedeutung für einen Prozess oder Service-Konsumenten (aus der CostCenter- und Betreiber-Perspektive) abschätzen – Kaufleute können hingegen zwar sehr gut Kosten, Gewinnausfälle und Schäden beziffern und damit Schadenswerte benennen, aber unmöglich Schwächen und Gefahren, technische Folgen und Eintrittswahrscheinlichkeiten in der IT ermitteln.
Hinzu kommt, dass der IT-Betrieb in der Regel als interner oder externer Dienstleister kaum oder keinerlei Einblicke in die Nutzung und die damit verbundenen Abhängigkeiten der durch ihn bereitgestellten Leistungen hat. So kann die IT aus dieser Nutzung abgeleitete Ziele nicht erkennen und damit letztlich nicht effektiv und effizient schützen.
Die ISO 27005:2018 führt aus diesem Grund den Begriff der Konsequenz ein (dazu später mehr). Das NIST beschreibt diese Problematik in SP 800-30 Rev.1 [3] unter 2.4.1 „Risk Assessments at the Organizational Tier“ und schlägt eine Normalisierung der Risiken auf organisatorischer Ebene durch Experten vor: „In decentralized organizations or organizations with varied missions/business functions and/or environments of operation, expert analysis may be needed to normalize the results from Tier 2 risk assessments.“
Schwächen der quantitativen Risikoanalyse
Obwohl innerhalb der IT-Organisation eine Folgenabschätzung für externe Leistungsempfänger kaum möglich ist, wird genau dies in der Regel verlangt. Dabei steht die IT organisatorisch auf einer Stufe mit beispielsweise Logistikern oder Rohstofflieferanten, ganz weit vorne in einer langen und komplexen Risikomanagement Kette von Abhängigkeiten. Eine quantitative Analyse von Schäden und Risiken ist an dieser Stelle unmöglich – vor allem einer internen IT, die oft aus der Ur-Organisation „gewachsen“ ist und nicht auf Basis von Verträgen mit definierten Service-Level-Agreements (SLAs), Haftungsbeschränkungen und -summen et cetera arbeitet. Zudem kann eine IT-Organisation unmöglich die Risikoaffinität des Leistungsnehmers kennen und somit auch keine anforderungs- beziehungsweise schutzbedarfsgerechte Technik und Prozesse bereitstellen.
Die IT-Organisation kann die Schutzbedürfnisse schon allein deshalb nicht bestimmen, weil sie die zur Ermittlung eines Risikowertes notwendigen Variablen nicht kennt. Hinzu kommt in der Regel noch das Unwissen über Klassifikationen und Volumen der durch den Konsumenten eingebrachten Informationen – dabei wäre dies eine der wichtigsten Grundvoraussetzungen für ein angemessenes Informationssicherheitsmanagement. Des Weiteren kennt sie meist weder die (technische) Umgebung noch die Prozesslandschaft, in der diese Werte Verwendung finden. Es müssen daher (mehr) künstliche Horizonte her, die Ziele setzen und Verantwortlichkeiten trennen!
Warum klassische Methoden versagen
Die klassischen Methoden funktionieren nach dem Bottomup-Prinzip: Man setzt am Anfang der Kette (ganz unten) an und kann in der Regel kaum über die Grenzen dieses ersten Kettenglieds hinaus in die Organisation oder Wertenutzung vordringen. „Wir erwarten, dass alles sicher ist – um Informationssicherheit soll sich die IT kümmern“ – diese häufige Sichtweise ist der erste methodische Fehler. Doch Informationssicherheit kann nicht „zugeliefert“ werden und ist nur bezahlbar, solange sie Angemessenheit und Ziele klar definiert oder standardisiert.
Der systematische Fehler vieler Methoden ist es, den nach Einschätzung des Autors primären Aspekt der Informationssicherheit zu ignorieren: dass diese nämlich in Abläufen oder Prozessen agiert. Weisen Prozesse Schwachstellen auf, ist es irrelevant, wie stark die darunterliegende Technik gesichert ist – die Information, der unterstützende Wert oder die Erreichung des Prozesszieles bleiben dennoch gefährdet. Dies ist der zweite methodische Fehler: Werte und unterstützende Werte sind nur auf Basis von Abläufen, die sie integrieren, nutzbar – und nur die Gefahren, die im Rahmen dieser Nutzung gegenüber integrierenden Prozessen auftreten können, sind relevant für eine Risikobewertung.
Dabei ist der Prozess das Alpha und Omega, er stellt das Rahmenwerk dar, definiert Ziele, Abläufe, Stakeholder, Kosten und Nutzen, bietet und bedient Schnittstellen, kennt Abhängigkeiten, behandelt Risiken und ermöglicht Chancen. Ohne die Sicherung der Zielerreichung und damit die Funktion von Prozessen zum zentralen Dreh- und Angelpunkt der Bestrebungen zu erheben, ist aus Sicht des Autors kein effizientes (und kaum ein effektives) Management der Informationssicherheit erreichbar, da dieses lückenhaft und ungerichtet bleiben muss. Ein bloßes „Scoping“ oder die Definition eines Kontexts, wie sie ISO/IEC 27005 oder DIN ISO 31000 vorsehen, genügt hier nicht.
Der dritte methodische Fehler ist es, Mitarbeiter oder Mitarbeitergruppen außerhalb der Grenzen ihres Erfahrungshorizonts einzusetzen. Niemand ist auf sich gestellt in der Lage, komplexe Prozessketten, Risiken, Folgen und Chancen kaufmännisch und technisch zu überblicken. Am Beispiel eines ACL-Antrags (bzw. Firewall-Freischaltung), also eines Prozesses, den jeder ITler heute kennt, wird die Tragweite deutlich: Netzwerk-Administratoren können unmöglich jede mögliche „Technologie“, Applikation und Systemarchitektur im Detail kennen, um so die Folgen (Chancen und Risiken) abzuschätzen, die sich durch eine Erweiterung der Kommunikationsmöglichkeiten auch nur eines Systems für den gesamten Systemverbund ergeben. Dies wird erst dadurch möglich, dass Kenntnisse über alle betroffenen Prozesse und Prozessziele inklusive ihrer Relevanz transparent gemacht werden (vgl. Abb. 1).
Prozessketten müssen gegliedert sein. Prozesse brauchen stark definierte Übergabepunkt und Schnittstellen sowie klar definierte Betriebsparameter und Ziele – sie sollen modular sein und nicht in die Domäne anderer Prozesse und Organisationen hineinreichen. Ein Schema der Prozesslandschaft (u. a. mit klaren Abhängigkeiten) ermöglicht es, Knoten mit hoher Kritikalität zu erkennen.

Abbildung 1: Um bei der Ermittlung von Risiken den begrenzten Horizont einzelner Ebenen zu überwinden, ist eine Top-down-Kommunikation notwendig
Shared Responsibility
Eine häufig anzutreffende Situation bei Risiko-Assessments ist, dass die Befragten zwei Szenarien miteinander vermischen: einerseits den Betrieb oder die Herstellung der Komponenten oder des Service (z. B. Operations und Administrations-Prozesse) und andererseits die Nutzung des Services oder Produkts (vgl. Abb. 2). Die Sicherheit in der Informationstechnik formuliert in ihren Standards Anforderungen an die Fertigung, nicht an das Produkt! Bei IT-Services ist eine Rückwirkungsfreiheit des Produkts auf den Bereitstellungsprozess jedoch oft nur eingeschränkt umsetzbar.

Abbildung 2: Produktions- und Produktsicherheit haben verschiedene Ziele, werden aber bei Risiko-Assessments häufig wild vermischt.
Sicherheit und Qualität
Zudem ist es in der Praxis der Regelfall, dass Anbieter oder Zulieferer von Diensten wie Komponenten die Risiken der Nutzung des Services/Produkts bewerten und verwalten. Dies mag im Einzelfall bei kleineren Anwendungen und Services noch umfänglich funktionieren – je generischer, vielseitiger oder umfangreicher aber Services und Produkte werden, desto mehr Risiken sind nur aus der Nutzerperspektive erkennbar.
Der technische Betreiber eines Services oder der Hersteller eines Produkts kann jedoch Risiken, die durch eine nutzerseitige Integration im Betriebs- und Konsumentenprozess entstehen, kaum erkennen. Ein gutes Beispiel, um dieses Dilemma zu verdeutlichen, ist die Bereitstellung virtueller Server: Der Serviceeigner kann zwar Risiken betrachten, die bei der Bereitstellung und Administration des Hypervisors entstehen, er kann aber unmöglich absehen, zu welchem Zweck ein Servicenutzer dieses System einsetzen wird und welche Risiken aus dieser Nutzung im Detail erwachsen.
Der Anbieter sollte allerdings serviceweite Gefahren (z. B. Ausfall oder Missbrauch) betrachten und die assoziierten Gefahren (nicht die Risiken!) gegenüber allen Servicenutzern transparent machen. Um Gefahren zu reduzieren, die ihm (und anderen) durch die Nutzung eines Services entstehen, ist es für den Servicebetreiber sinnvoll, die Nutzung technisch (Berechtigungsmanagement, Zugriffsbeschränkung, Quality of Service, Last-Quota, Isolation, Verschlüsselungsverfahren etc.) oder vertraglich (Terms of Use) einzuschränken, indem er „gefährliche“ und illegitime Use-Cases explizit ausschließt (Blacklist) oder explizit zugelassene Use-Cases benennt (Whitelist).
Dieses Vorgehen ist aus dem Bereich der Produktsicherheit jedem bekannt, der einmal über ein Begleitheft eines Konsumentenprodukts den Kopf geschüttelt hat. Auch im Endkundensegment der IT findet man recht häufig Beschränkungen nach dem Blacklist-Prinzip: Hoster verbieten beispielsweise meist Glücksspielaktivitäten, den Vertrieb von Alkohol, Tabak und Medikamenten, die Verbreitung von Erotika sowie Copyright-Verstöße – und Internetserviceprovider (ISP) behalten sich das Recht vor, „zum Schutz der Netzstabilität“ Bandbreiten und Datenvolumen von Nutzern zu beschränken.
Die Informationssicherheit von Produkten und Dienstleistungen ist in den Augen des Autors ein klares Qualitätsmerkmal. Verbindliche Sicherheitsmerkmale und ihre Mindestanforderungen sind im Rahmen der Produktqualität in der IT jedoch eher vage definiert – abseits des Datenschutzes wird die Anforderungslage (abgesehen von stark regulierten Branchen) sehr dünn. Neben dem Produkthaftungsgesetz und der Datenschutzgrundverordnung ist – etwa in Bezug auf „Smarte IT“ und IoT-Geräte, die Plattform, Software und Hardware koppeln – noch das Telekommunikationsgesetz zu nennen (z. B. § 90 „Missbrauch von Sende- oder sonstigen Telekommunikationsanlagen“ und § 94 „Einwilligung im elektronischen Verfahren“).
Vorgaben und Prüfungen
Verbindliche technische Vorgaben für Produkte sucht man jedoch vergeblich. Aus dem Umfeld des Schutzes kritischer Infrastrukturen (KRITIS) kommt zumindest die – allerdings ebenfalls unspezifische – Anforderung, „dem Stand der Technik“ entsprechende Informationssicherheitsmaßnahmen einzusetzen. Hierzu existiert immerhin eine ziemlich umfassende und aktuelle Handreichung des TeleTrustT [4].
Schaut man sich bei den Gütesiegeln um, wird man hierzulande lediglich bei TÜViT fündig, die unter anderem die Zertifizierung „Trusted Product Security (TPS) für IT-Produkte“ in 5 Stufen (SEAL-*) und die Zertifizierung mobiler Anwendungen, Services, Lösungen und ihrer Infrastruktur anbieten. TPSZertifizierungen haben einen hohen Produktbezug, ihr Verbreitungsgrad ist jedoch, zumindest gemessen an den veröffentlichten Zertifikaten, sehr gering. Geprüft wird, ob die durch das Produkt oder die Anwendung zugesicherte Qualität, also eigene technische Sicherheitsanforderungen, erreicht wurden. Betrachtet werden des Weiteren die Eignung von Architektur und Designs für den Einsatzzweck, die angewandten Mittel der Informationssicherheit im Entwicklungsprozess, die Betriebsdokumentation (bei Level 4 und 5), Freiheit von Schwachstellen durch Penetration-Tests (Level 2 bis 5), es erfolgt eine Sourcecode-Analyse (Level 4 und 5) und eine Betrachtung des Änderungsmanagements (Level 5). Auch hier findet man aber leider keine handfesten Minimalanforderungen, die als Richtlinie dienen könnten.
Zwischenfazit: Eine klare Trennung zwischen produzenten- und nutzungsrelevanten Gefahren ist ein wichtiger Bestandteil der Shared-Responsibility-Strategie und sollte frühzeitig bei der Planung von Dienstleistungen und Produkten Beachtung finden. Dabei ist es für die Akzeptanz der gebotenen Leistung nicht unwesentlich, eine nutzungsorientierte Abwägung zwischen der angestrebten Sicherheit (Risikoarmut), dem Komfort und dem avisierten Freiheitsgrad für den Nutzerkreis unter Einhaltung der Datenschutzregularien zu treffen.
Werte- und Risikobegriff
Das hier im weiteren Verlauf geschilderte Vorgehen ist nach Meinung des Autors konform zu den in ISO/IEC 27005:2018 beschriebenen Anforderungen. Die Norm behandelt „all relevant assets“ und definiert in 8.2.2 „Identification of assets“: „An asset is anything that has a value to the organization.“ Man darf also auch Prozesse als relevante Werte im Rahmen des eigenen Risikomanagements definieren.
Kapitel 7.3 weist im Übrigen auf die Notwendigkeit der Identifikation von Risiken hin, die durch Grenzen des Betrachtungsraums (Scopes) entstehen, und verweist auf Geschäftsprozesse, organisatorische Funktionen und Strukturen sowie Schnittstellen: „… the organization should consider the following information: … business processes; the organization´s functions and structure; … interfaces“.
Die Erhebung von Schwächen und Anfälligkeiten von Prozessen ist ebenfalls normkonform, denn Kapitel 8.2.5 „Identification of Vulnerabilities“ besagt: „Vulnerabilities can be identified in following areas: organizations; processes and procedures; management routines.“ All dies stellt eine starke argumentative Basis für ein prozessorientiertes Risikomanagement dar.
Was ist eigentlich ein „Risiko“?
Aus der (ggf. eingeschränkten ITler-) Perspektive des Autors könnte eine allgemeingültige Definition im kaufmännischen Sinne lauten: Risiko ist die Möglichkeit (und die Wahrscheinlichkeit dieser Möglichkeit) des Verlusts von Werten und der Nichterreichung von Zielen durch Ereignisse, die einen Einfluss auf den geplanten Ablauf haben. Dabei sind in aller Regel negative Einflüsse und Schäden in Euro gemeint – diese umfassen:
- operative Kosten für die betroffenen Prozesse einschließlich ihrer Infrastruktur sowie Personal (Miete, Strom, Personal, Heizung etc.) – Kosten also, die auch dann anfallen, wenn ein Prozess gestört ist oder nicht zum geplanten Ergebnis führt
- den Verlust von Profiten (Gewinnausfall) durch die Unmöglichkeit, bei einer Beeinträchtigung des Prozesses Chancen wahrzunehmen
- alle Kosten, die zur Behandlung des Ereignisses, der Schadenseindämmung und Wiederherstellung des Zielzustands des Prozesses anfallen (Recovery), sowie Schäden durch Haftung, Minderung, Vertragsstrafen und Regressforderungen sowie mögliche Strafen bei Gesetzesverstößen (z. B. nach DSGVO)
- Schäden, die durch unmittelbare Folgeschäden beziehungsweise „Konsequenzen“ anfallen (z. B. Materialkosten in der Produktion)
Gerade der letzte Punkt ist wichtig, wird von ITlern aber gerne übersehen: Er behandelt den Übergang von Wirkungen aus dem virtuellen Raum zur physischen Welt, der seit dem Beginn der automatisierten Fertigung bis hin zur Home-Automation immer wichtiger wird.
Nicht erfassen sollte man hingegen nach Meinung des Autors Kosten, die zu einer Vermeidung oder Schadensbegrenzung bei erneuten/zukünftigen Ereignissen entstehen, also Maßnahmen des kontinuierlichen Verbesserungsprozesses (KVP) und damit verbundener Aufwand.
Interessanterweise propagieren die ISO/IEC 27005 und DIN ISO 31000 an dieser Stelle verschiedene Modelle: Die ISO/IEC 27005 verwendet „Impact Criteria“ (Kapitel 7.2.3), wohingegen die ISO 31000 (Kapitel 6.3.4) den Begriff „Consequence Criteria“ nutzt. Der Autor favorisiert den zweiten Ansatz, da „Konsequenzen“ nicht nur auf die unmittelbaren Schäden, sondern auch im Sinne von Folgen und Folgeschäden darüber hinaus greifen.
Risikoidentifikation
Um Risiken (und Chancen) identifizieren zu können, ist es im Umkehrschluss zur Betrachtung des Versagens klassischer Methoden sinnvoll, im Top-down-Verfahren die Prozess-Struktur zu analysieren – und nicht „bottom up“ auf Basis solitärer Assets vorzugehen. Die Strukturen lassen sich dabei in Prozesse, kleinere Teilprozesse oder Prozeduren, Funktionen oder Methoden sowie Schnittstellen gliedern (vgl. Abb. 3). Dabei sollte man unbedingt eineindeutige Bezeichner (z. B. UUIDs) für Komponenten, Werte, Prozesse, Prozeduren und Funktionen nutzen, um klare Referenzen oder Querverweise herstellen zu können.
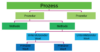
Abbildung 3: Gliederung von Prozessen und zugehörigen Werten
Wie man „in den Flow“ kommt
Besteht erst einmal eine Reihe von Ablaufdiagrammen oder Process-Flows, entsteht automatisch eine Mehrdimensionalität, mit deren Hilfe Elemente hoher Kritikalität über die Anzahl von Referenzen/ Zeigern identifizierbar werden (das funktioniert übrigens auch gut mit Objekten in Firewallregelwerken). PowerPoint ist allerdings kein geeignetes Werkzeug, um ein derartiges Beziehungsmodell abbilden und parsen zu können – empfehlenswert sind etwa Datenformate, die sich zur Beschreibung von Objekten und Bäumen eignen (z. B. XML oder JSON).
Solche Diagramme müssen nicht bis ins letzte Detail vollständig sein, sollten aber zumindest alle relevanten zentralen (unterstützenden) Werte im Rahmen des Scopes „Informationssicherheitsmanagement“ abdecken. Leistungen, Services und Komponenten externer Organisationen können dabei auch als Blackbox auftreten. Wessen Fokus beispielsweise nicht auf BCM oder HR liegt, der braucht Räumlichkeiten und Personalverfügbarkeit nicht unbedingt zu betrachten. Derartige Entscheidungen sollte man allerdings wohlüberlegt treffen.
Stehen die gewünschten Daten zur Verfügung, empfiehlt es sich, auf Basis der FMEA-Methodik von grob nach fein die Kritikalität beziehungsweise Relevanz für den Erfolg des Prozesses oberster Ordnung zu ermitteln – mit zunehmender Analysetiefe steigen dabei Komplexität und Aufwand. Eine Alternative stellt eine Tier-2-Analyse nach NIST SP 800-30 Rev.1 [3] dar – ein Nachteil ist jedoch, dass immanente Zusammenhänge nicht zwangsläufig transparent werden.
Wichtig muss nicht dringlich sein
Kritikalität sollte dabei sowohl hohe Wichtigkeit als auch Dringlichkeit bedeuten. Ein Beispiel: Für den Unternehmenserfolg sind Personalbeschaffung und -qualifikation von hoher Wichtigkeit, aber geringer Dringlichkeit – ein Unternehmen wird nicht scheitern, weil der Personalreferent drei Tage mit Schnupfen im Bett liegt oder eine Awareness-Schulung um zwei Wochen verschoben werden muss. Wichtig ist, was es für den übergeordneten Prozess bedeutet, wenn ein Teilprozess, eine Funktion oder Schnittstelle nicht bereitsteht oder integrierte Informationen offengelegt werden und wie schnell die erwarteten Folgen zu einer Gefahr und dann zu einem Risiko für den Prozesserfolg werden.
Ist dies auf Ebene der Prozesse erledigt, nimmt man sich die Prozesse mit hoher Kritikalität vor und betrachtet unterstützende und primäre Werte innerhalb des jeweiligen Teilprozesses hin auf ihre Kritikalität. Hierbei sind Wichtigkeit der Funktion (Verfügbarkeit, Integrität) und Vertraulichkeit als primäre Schutzziele relevant.
Hat man diese Bewertung für eine Reihe von Prozessen oder Teilprozessen vollzogen, werden einige Funktionen und damit verbundene Werte mit hoher Wahrscheinlichkeit mehrfach erscheinen – etwa der Serverraum, das Netzwerk oder Ihr freundlicher Haustechniker Herr Müller. Somit ist nun die Erhebung der Tiefe der Abhängigkeit als Dimension für die Kritikalität einer Funktion und eines Wertes im Prozessverbund hinzugekommen.
Zu beachten ist, dass Prozesse zwar eine Vertraulichkeit besitzen können, diese im Rahmen der Informationssicherheit jedoch (leider) kaum betrachtet wird – und dass Daten zwar einen Zweck, aber keine Funktion haben: Sie liegen die meiste Zeit herum, parametrisieren Prozesse oder dienen der Nachvollziehbarkeit von Ereignissen und Resultaten.
Der Autor trennt Information daher in zwei Klassen:
- Informationen zur Parametrisierung eins Prozesses („Prozesskonfiguration“) – zum Beispiel ein Warenkatalog oder Nutzerkonto mit Adressdaten und Zahlungsinformationen eines Webshops – sowie
- Status- und Protokoll-Informationen – etwa Versand-, Transaktions- oder Rechnungsstatus
Die folgenden Teile dieses Beitrags befassen sich unter anderem mit qualitativer, quantitativer sowie holistischer Risikoanalyse, einer möglichen Gewichtung von Kritikalität, perspektivischen Gefährdungen in der Informationssicherheit sowie Standardisierungsfragen.
Bastian Angerstein (T.I.S.P, ISO 27001 Lead Auditor) ist ehemaliger Softwareentwickler und seit 2008 zunehmend im Bereich der Informationssicherheit und Risikoverwaltung tätig – heute im Cloud-Umfeld bei der Robert Bosch GmbH.
Literatur
[1] Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin), Mindestanforderungen an das Risikomanagement – MaRisk, Rundschreiben 09/2017, www.bafin.de/SharedDocs/Veroeffentlichungen/DE/Rundschreiben/2017/rs_1709_marisk_ba.html
[2] International Electrotechnical Commission (IEC), Failure modes and effects analysis (FMEA and FMECA), IEC 60812:2018, www.vde-verlag.de/iec-normen/225834/iec-60812-2018.html
[3] National Institute of Standards and Technology (NIST), Guide for Conducting Risk Assessments, NIST SP 800-30 Rev. 1, September 2012, https://csrc.nist.gov/publications/detail/sp/800-30/rev-1/final
[4] TeleTrusT – Bundesverband ITSicherheit e. V., Handreichung zum „Stand der Technik“ technischer und organisatorischer Maßnahmen, Februar 2019, www.teletrust.de/fileadmin/docs/fachgruppen/2019-02_TeleTrusT_Handreichung_Stand_der_
Technik_in_der_IT-Sicherheit_DEU.pdf