
Management und Wissen : Dreiklang gegen Angreifer unter dem Radar : Mikrosegmentierung ergänzt kontextschaffende Mechanismen und bremst Angreifer
Mehr Alerts bedeuten nicht automatisch mehr Sicherheit – IT-Sicherheitsexperten brauchen Kontext und Priorisierung, um ihre begrenzten Ressourcen wirksam einsetzen zu können. Visibility, Observability und Mikrosegmentierung ermöglichen es Organisationen im Zusammenspiel, in der kritischen Zeit zwischen Alarm und dem Stoppen eines Angriffs die Beweglichkeit von Angreifern und die Auswirkungen von Attacken einzuschränken.
Unternehmen verfügen heute über mehr Daten denn je, die für die IT-Sicherheit relevant sein können: Detection-and-Response-Lösungen erzeugen kontinuierlich Alerts zu Anomalien bei Endpoints, Workloads, Identitäten und im Netzwerkverkehr. Theoretisch sollte dies die Sicherheit verbessern – in der Praxis führt es jedoch häufig zur Überlastung von Teams. Jede Warnmeldung muss schließlich geprüft, verstanden und priorisiert werden, bevor man Maßnahmen ergreifen kann.
Dem 2025 Global Cloud Detection and Response Report [1] zufolge erhalten deutsche Sicherheitsteams im Durchschnitt 2416 Alerts pro Tag – der höchste Wert unter den untersuchten Ländern. Übersteigt dieses Volumen die verfügbaren Kapazitäten, wird Alert-Fatigue zu einem strukturellen Problem.
Im Ergebnis zeigt sich ein Paradox: Sicherheitsteams verfügen über mehr Informationen als je zuvor, gewinnen daraus aber nicht zwangsläufig mehr Klarheit. Zeit geht verloren, weil Anomalien bewertet werden müssen, die möglicherweise harmlos sind, während echte Angriffe unbemerkt voranschreiten.
Ausbreitung moderner Angriffe
Erschwert wird dies durch die Art und Weise, wie Cyberangriffe heute typischerweise ablaufen: In vielen Fällen beginnt ein Angriff nicht mit einer sofort sichtbaren Störung. Stattdessen versuchen Angreifer* zunächst, möglichst unauffällig Zugriff auf einen weniger geschützten Teil der IT-Umgebung zu erlangen, etwa auf einen Endpoint oder eine Anwendung. Von dort aus bewegen sie sich dann Schritt für Schritt lateral durch die IT-Umgebung weiter.
Dabei gehen sie so diskret wie möglich vor. Sie nutzen legitime Benutzerkonten, bewegen sich entlang bestehender Kommunikationspfade und missbrauchen vorhandene Tools wie PowerShell, WMI oder SSH („Living off the Land“, LOTL). Ihr Ziel ist es zunächst, die Umgebung zu erkunden, weitere Systeme zu erreichen und Berechtigungen auszuweiten, bevor sie dann durch Datenexfiltration, Verschlüsselung oder Unterbrechungen des Betriebs sichtbaren Schaden verursachen.
Besonders problematisch ist diese laterale Bewegung nicht, weil sie grundsätzlich unsichtbar wäre, sondern weil sie mit klassischen Tools schwer zu erkennen ist: Administrativer Zugriff auf eine Datenbank, eine neue Verbindung zwischen zwei Workloads oder ungewöhnliche Kommunikation zwischen zwei Servern können isoliert betrachtet plausibel erscheinen. Erst wenn man diese Signale im Kontext betrachtet, wird deutlich, ob sich hier ein Angreifer schrittweise durch die Umgebung bewegt.
Grenzen von Detection and Response
Detection and Response ist und bleibt ein zentraler Bestandteil moderner Sicherheitsarchitekturen – entsprechende Lösungen erkennen Anomalien, lösen Alerts aus und können erste reaktive Maßnahmen einleiten, wenn Aktivitäten vom erwarteten Verhalten abweichen. Viele Unternehmen nutzen dafür mehrere Tools parallel, etwa EDR, NDR, XDR oder ein SIEM. In ihrer Leistungsfähigkeit liegt kein Problem, wohl aber in ihrer Perspektive.
Diese Werkzeuge erzeugen Alarmmeldungen, die für sich genommen oft nicht genügend Kontext liefern, um eine verlässliche Entscheidung zu treffen: Ob ein Signal sicherheitsrelevant ist, lässt sich häufig erst beurteilen, wenn es mit weiteren Informationen verknüpft wird – etwa mit dem betroffenen System, der dahinterstehenden Identität oder dem normalen Kommunikationsverhalten. Sicherheitsteams müssen daher mehr leisten, als nur zu erkennen, dass etwas ungewöhnlich ist.
Vielmehr ist zu ergründen, ob ein Alert tatsächlich auf bösartiges Verhalten hindeutet und warum er gegebenenfalls Priorität haben sollte. Dieser Schritt kostet Zeit: Alerts müssen geprüft, priorisiert und näher untersucht werden. Währenddessen kann sich ein Angreifer aber bereits weiter in der Umgebung bewegen. Das Problem besteht daher nicht allein in der Menge der Warnmeldungen, sondern auch in der Verzögerung zwischen Erkennung, Bewertung und Reaktion.
Von Visibility zu Observability
Eine bessere Erkennung beginnt mit Visibilität: Unternehmen müssen verstehen, welche Systeme, Workloads und Anwendungen tatsächlich miteinander kommunizieren, welche Abhängigkeiten bestehen und welche Verbindungen für den Betrieb notwendig sind. Ohne dieses Verständnis bleiben auch heikle Kommunikationspfade offen, unnötige Verbindungen bestehen und Abhängigkeiten unentdeckt.
Besonders wichtig ist diese Visibilität in hybriden und cloudbasierten Umgebungen, wo Anwendungen verteilt in Rechenzentren, Public Clouds und Container-Plattformen ablaufen. Workloads werden dynamisch erstellt und verschwinden wieder, während Kommunikationsbeziehungen sich laufend ändern. Traditionelle Ansätze wie statische Configuration-Management-Database-(CMDB)-Tabellen, lange CVE-Listen und abstrakte Risikowerte bilden diese Realität nur begrenzt ab.
Visibilität allein beantwortet jedoch nicht die entscheidende Frage, ob eine beobachtete Verbindung tatsächlich ein Risiko darstellt – zu sehen, dass eine Verbindung existiert, reicht nicht aus. Sicherheitsteams müssen feststellen können, ob sie erwartet ist, ob sie sensible Assets betrifft und ob sie einen Pfad schafft, den ein Angreifer ausnutzen könnte.
Hier setzt Observability an: Während Visibilität zeigt, was geschieht, erklärt Observability, warum es geschieht. Sie liefert den notwendigen Kontext, um eine Anomalie richtig zu bewerten: Welche Systeme kommunizieren miteinander? Ist diese Verbindung Teil des normalen Betriebs? Welche Identität steht dahinter? Und weist das beobachtete Verhalten tatsächlich auf einen Angriff hin?
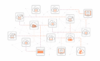
Um diese Fragen zu beantworten, müssen Sicherheitsteams Kommunikationsflüsse, Workloads, Identitäten und die Relevanz von Assets in einer gemeinsamen Sicht zusammenführen. Erst dann wird deutlich, ob ein neuer Kommunikationspfad normal ist oder möglicherweise auf bösartiges Verhalten hindeutet.
Eine Verbindung zwischen zwei Workloads ist ja nicht automatisch verdächtig. Relevant wird sie erst, wenn sie nicht zum normalen Verhalten passt, eine sensible Ressource betrifft oder einen neuen Pfad in einen besonders kritischen Bereich des Netzwerks schafft. Dieser Kontext macht aus Alerts verwertbare Erkenntnisse statt bloßer Symptome. Observability ermöglicht es Sicherheitsteams, sich auf die Alerts zu konzentrieren, die tatsächlich ein Risiko signalisieren, und den Rest auszublenden.
Hilfreicher Kontext durch künstliche Intelligenz
Eine Möglichkeit, Observability in komplexen IT-Umgebungen umzusetzen, ist ein Security-Graph (vgl. auch [2]), der nicht nur einzelne Systeme oder Ereignisse, sondern auch die Beziehungen zwischen ihnen erfasst. Dazu gehören Kommunikationsbeziehungen zwischen Workloads, Abhängigkeiten zwischen Anwendungen, Zugriffe von Identitäten auf Systeme sowie Verbindungen zwischen unterschiedlichen Bereichen der IT-Umgebung.
Aus vielen einzelnen Signalen entsteht dadurch ein zusammenhängendes Bild. Sicherheitsteams können einen Alert nicht nur isoliert betrachten, sondern ihn in den Kontext der gesamten Umgebung einordnen. So lassen sich beispielsweise eine neue Verbindung zwischen Entwicklungs- und Produktionssystemen, ein ungewöhnlicher Datenbankzugriff oder die Kommunikation zwischen bislang getrennten Cloud-Bereichen fundierter bewerten.
Künstliche Intelligenz (KI) kann diesen Ansatz unterstützen, indem sie Muster im normalen Verhalten erkennt, Abweichungen sichtbar macht und Alerts mit zusätzlichem Kontext anreichert. Der Mehrwert liegt dabei nicht in „mehr KI“, sondern in der Nutzbarmachung ihrer Fähigkeit, große Mengen an Signalen zu korrelieren und nach Relevanz zu priorisieren.
In hybriden Umgebungen setzt ein solches Lagebild voraus, Telemetriedaten aus unterschiedlichen Quellen zusammenzuführen – etwa aus Cloud-Umgebungen, Rechenzentren, Endpoints, Identitäten und bestehenden Netzwerkkontrollen. In vielen Organisationen kommen dabei sowohl agentenbasiert erhobene Daten als auch „agentenlose“ Informationen aus Firewall- und Policy-Telemetrie zum Einsatz. Dadurch lassen sich reale Datenflüsse, riskante Kommunikationspfade und mögliche Policy-Lücken besser nachvollziehen – auch in Bereichen, in denen die Sichtbarkeit bislang eingeschränkt war.
Erkennung allein ist noch kein Schutz
Auch eine bessere Erkennung und Einordnung stoppt einen Angriff nicht automatisch. In einem realen Vorfall kommt es aber darauf an, die Ausbreitung schnell und möglichst gezielt einzudämmen.

Genau hier stoßen viele Sicherheitsarchitekturen an ihre Grenzen: Sie erkennen verdächtige Aktivitäten und erzeugen Alerts, verfügen aber nur eingeschränkt über Möglichkeiten, Bewegungen eines Angreifers zu begrenzen, ohne kritische Dienste oder größere Teile der IT-Umgebung zu beeinträchtigen. Müssen Teams erst während eines Vorfalls entscheiden, welche Verbindungen unterbrochen und welche Systeme isoliert werden können, geht wertvolle Zeit verloren – Zeit, in der sich ein Angreifer weiter durch die IT-Landschaft bewegen kann.
Daher sind zwei Fähigkeiten erforderlich: Zum einen müssen Organisationen während eines laufenden Vorfalls Kommunikationspfade gezielt kontrollieren können. Zum anderen benötigen sie eine Sicherheitsarchitektur, die laterale Bewegung bereits standardmäßig erschwert. Dies entspricht dem Grundgedanken von Zero Trust (ZT).

Mikrosegmentierung schützt
Ein zentraler Baustein von Zero Trust ist Mikrosegmentierung – sie ist gleichzeitig ein wirkungsvolles Mittel, um die Ausbreitung von Angriffen zu begrenzen. Dieser Ansatz beruht nicht zuletzt darauf, dass Systeme, Anwendungen und Workloads nur über jene Verbindungen kommunizieren dürfen, die für den Betrieb erforderlich sind – alle anderen Verbindungen werden standardmäßig verweigert. Damit werden große, implizite Vertrauensbereiche durch kleinere, explizit definierte Zonen ersetzt. Das schränkt die Fähigkeit eines Angreifers, sich lateral zu bewegen, von Anfang an ein – auch bevor ein Angriff überhaupt als solcher erkannt wird.
In hybriden Multi-Cloud-Umgebungen ist diese Granularität unverzichtbar. Anwendungen bestehen dort aus vielen Komponenten, Workloads kommunizieren über verschiedene Plattformen hinweg und kritische Systeme befinden sich längst nicht mehr innerhalb fester Netzwerkgrenzen. Mikrosegmentierung setzt daher auf Workload- und Anwendungsebene an: Erforderliche Verbindungen werden erlaubt, nicht benötigte Kommunikationspfade blockiert.
Dadurch wird der Bewegungsspielraum von Angreifern begrenzt, ein unentdeckter Einbruch führt nicht automatisch dazu, dass weitere Systeme erreichbar sind. Kommt es zu einem Vorfall, kann die Eindämmung schneller und gezielter erfolgen, weil die Umgebung bereits darauf ausgelegt ist, Auswirkungen zu begrenzen.
Pragmatische Umsetzung von Mikrosegmentierung
Mikrosegmentierung galt lange als komplex in der Umsetzung und schwer mit betrieblichen Anforderungen vereinbar – diese Bedenken sind auch durchaus nachvollziehbar. Gleichzeitig wird Segmentierung in modernen hybriden Umgebungen heute aber anders umgesetzt als noch vor einigen Jahren.
Verändert hat sich weniger das Prinzip als die Art der Implementierung: Segmentierung muss heute nicht mehr ausschließlich auf statischen Netzwerkgrenzen oder manuell gepflegten Regelwerken beruhen. Richtlinien lassen sich zunehmend aus tatsächlichem Kommunikationsverhalten ableiten und schrittweise einführen. Dafür sind weder von Beginn an vollständige Daten noch sofort sehr feingranulare Regeln erforderlich.
In der Praxis segmentieren Organisationen selten ihre gesamte Umgebung auf einmal – und das müssen sie auch nicht. Ein sinnvoller Ausgangspunkt ist die Definition kritischer Bereiche: besonders sensible Anwendungen, privilegierte Zugriffspfade, zentrale Datenbestände oder Übergänge zwischen verschiedenen Teilen der Infrastruktur (etwa zwischen IT und Operational Technology, OT – vgl. Abb. 4). Denn dort hätte laterale Bewegung besonders große Auswirkungen und dort kann Segmentierung das Risiko früh reduzieren.
Sobald reale Kommunikationsmuster sichtbar werden, können Teams unterscheiden, welche Zugriffe für den Betrieb notwendig sind und welche Verbindungen vermeidbare Exponierung darstellen. Auf dieser Grundlage lassen sich Richtlinien schrittweise einführen: zunächst breitere Einschränkungen gegen offensichtliche Risiken, später feinere Regeln auf Basis eines wachsenden Verständnisses der Umgebung.
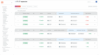
Moderne Plattformen unterstützen diesen inkrementellen Ansatz, indem sie übergeordnete Policy-Vorgaben in eine konsistente Durchsetzung über verschiedene Umgebungen und native Kontrollen hinweg übersetzen. Zudem ermöglichen sie es, Regeln vor der vollständigen Durchsetzung zu modellieren und zu testen. So lässt sich prüfen, welche Auswirkungen diese Richtlinien auf den Normalbetrieb hätten, bevor man sie produktiv anwendet.
- das reduziert das Risiko unbeabsichtigter Unterbrechungen und erleichtert ebenfalls eine schrittweise Einführung
Entscheidend ist, nicht auf einen idealen Ausgangszustand zu warten! Mikrosegmentierung ist kein einmaliges Projekt, sondern ein iterativer Prozess. Organisationen, die mit vorhandenen Informationen beginnen und ihre Maßnahmen schrittweise ausbauen, können Risiken früher reduzieren als solche, die zunächst vollständige Visibilität oder perfekte Datenqualität anstreben.
Warum Visibilität, Observability und Mikrosegmentierung zusammengehören
Visibility, Observability und Mikrosegmentierung entfalten ihren Nutzen vor allem im Zusammenspiel:
- Visibility macht Verbindungen und Anomalien erkennbar.
- Observability liefert den Kontext, um Risiken zu bewerten.
- Mikrosegmentierung schafft die Möglichkeit, erkannte Risiken technisch zu begrenzen – sowohl vorbeugend als auch während eines Vorfalls.
Ohne Visibilität riskieren Organisationen, jene Kommunikationspfade zu übersehen, die kontrolliert werden müssen. Ohne Observability bleibt unklar, welche dieser Pfade tatsächlich kritisch sind. Und weil die Erkenntnisse aus Visibilität und Observability an sich erst einmal analytisch bleiben, braucht man noch die Mikrosegmentierung: Sicherheitsteams sehen und verstehen ansosnten zwar das Risiko, können die Bewegungsfreiheit eines Angreifers aber nur begrenzt einschränken.
Fazit
Angriffe erfolgen heute immer schneller und stärker automatisiert. KI kann auch aufseiten der Angreifer Abläufe beschleunigen und damit die Zeit verkürzen, die Verteidigern für Erkennung, Entscheidung und Reaktion bleibt. Die zentrale Frage lautet daher nicht mehr nur, ob verdächtige Aktivitäten rechtzeitig erkannt werden. Entscheidend ist auch, wie weit sich ein Angreifer noch bewegen kann, während Sicherheitsteams den zugehörigen Alert auswerten.
Eine belastbare Cyberabwehr muss längst mehr leisten als reine Alarmierung. Sie muss Auffälligkeiten erkennen, sie im Kontext bewerten und die Ausbreitung eines Angriffs begrenzen können – möglichst bevor aus einem einzelnen Sicherheitsvorfall ein größerer Schaden entsteht. Erst diese drei Fähigkeiten zusammen schaffen eine Sicherheitsarchitektur, die Alert-Fatigue reduziert, Reaktionen beschleunigt und die Auswirkungen unvermeidlicher Sicherheitsvorfälle begrenzt.
Im Zeitalter der KI misst sich Cyberresilienz auch daran, ob dieser Wandel gelingt: weg von reiner Alarmierung, hin zu einer Verteidigung, die schneller erkennt, präziser bewertet und die Ausbreitung von Problemen wirksam begrenzt – sowohl im Vorfeld als auch während eines Angriffs.
Alex Goller ist Principal Solutions Architect bei Illumio.
Literatur
[1] Illumio, The 2025 Global Cloud Detection and Response Report, Oktober 2025, www.illumio.com/de/resource-center/global-cloud-detection-and-response-report-2025 (Registrierung erforderlich)
[2] Knoten und Kanten für die Security, Graphdatenbanken in der IT-Sicherheit: Vernetzte Datenanalysen für strukturellen Sicherheitskontext, 2026# 2, S. 68, www.kes-informationssicherheit.de/print/titelthema-graph-datenbanken/knoten-undkanten-fuer-die-security/ (<kes>+)