
Graphdatenbanken in der IT-Sicherheit : Knoten und Kanten für die Security : Graphdatenbanken in der IT-Sicherheit: Vernetzte Datenanalysen für strukturellen Sicherheitskontext
Angreifer denken in Netzwerken – Verteidiger in Listen. Wo Cyberkriminelle vernetzte Pfade nutzen, um sich lateral durch Unternehmensnetzwerke zu bewegen, stoßen klassische Security-Analysen bisweilen an ihre Grenzen, warnt unser Autor: Graphdatenbanken können solche Limitierungen aufbrechen.
Klassische Sicherheitsarchitekturen arbeiten überwiegend listen- und ereigniszentriert: Sie erfassen Logeinträge, Alerts, Benutzerkonten oder Schwachstellen in Tabellen, Ticketsystemen und Dashboards. Das Problem: Sie treffen dabei auf hochgradig vernetzte IT-Landschaften – einschließlich verteilter Cloud- und On-Premises-Umgebungen, hybrider Netzwerke, containerisierter Workloads, föderierter Identitäten, rollenbasierte Berechtigungsketten und einer stetig wachsenden Zahl veröffentlichter Schwachstellen.
Listenzentrierte Modelle geraten mit ihrer Struktur an Grenzen, da sie Sicherheitsinformationen in Einzellogiken zerlegen: Das Security-Information-andEvent-Management-System (SIEM) bewertet Events, das Identity-and-Access-Management-(IAM)-System verwaltet Rollen, Schwachstellen-Scans liefern CVE-Listen, Cloud-Tools überwachen Konfigurationen et cetera – Beziehungen zwischen diesen Datenquellen bleiben jedoch implizit. Komplexe Abhängigkeiten, etwa zwischen Identität, Netzwerkpfad und verwundbarem Dienst, lassen sich nur mit hohem manuellem Aufwand rekonstruieren. Zugleich erzeugt ein fragmentierter Tool-Mix große Datenmengen, ohne ein konsistentes Gesamtbild zu liefern.
Während Angreifer systematisch entlang erreichbarer Pfade vorgehen, fehlt Verteidigern oft genau dieser Beziehungskontext. Moderne Sicherheitswerkzeuge sollten daher Zusammenhänge strukturell erfassen. Hier liefern graphbasierte Ansätze Vorteile: Sie bilden Infrastrukturen, Identitäten, Berechtigungen und Schwachstellen als vernetztes Modell ab und machen Angriffspfade systematisch analysierbar.
Grundkurs Graphdatenbanken
Graphtechnologie ist keine neue Erfindung, ihre Grundlagen stammen aus der Graphentheorie der Mathematik des 18. Jahrhunderts. Mit der wachsenden Vernetzung digitaler Systeme und spätestens seit großskaligen Anwendungen wie dem Google Knowledge Graph (2012) hat sich das Modell jedoch von einem theoretischen Konzept zu einer praktischen Architektur für komplexe Datenlandschaften entwickelt.
Knoten, Kanten, Labels, Eigenschaften – Labeled-Property-Graph
Ein Graph besteht aus Knoten (Nodes) und Kanten (Edges). Knoten repräsentieren Entitäten – etwa Benutzer, Server, Anwendungen oder Schwachstellen. Kanten beschreiben die Beziehungen zwischen diesen Entitäten, beispielsweise „hat Zugriff auf“, „läuft auf“ oder „ist verbunden mit“.
Im sogenannten Labeled-Property-Graph-Modell können sowohl Knoten als auch Kanten Eigenschaften (Properties) tragen – etwa Zeitstempel, Versionsnummern oder Risikowerte. So entsteht kein abstraktes Netz, sondern ein semantisch angereichertes Modell realer IT-Strukturen.
Traversierung statt Joins
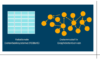
In relationalen Datenbanken (bzw. relationalen Datenbank-Managementsystemen, RDBMS) werden Beziehungen über Fremdschlüssel modelliert und zur Laufzeit mittels Joins (Verbunde) berechnet (vgl. Abb. 1).
Abbildung 1: Tabellen und Fremdschlüssel (RDBMS) versus Knoten und Kanten (Graphdatenbank) verdeutlichen den zentralen Unterschied im Datenmodell.
In Graphdatenbanken sind Beziehungen hingegen direkt gespeichert und unmittelbar adressierbar: Abfragen erfolgen durch Traversierung – also durch das gezielte Folgen von Kanten.
Für Sicherheitsanalysen bedeutet das: Statt Tabellen zu verknüpfen, lässt sich unmittelbar prüfen, über welche Pfade beispielsweise ein Benutzer ein sensibles System erreicht oder welche Systeme von einer kompromittierten Identität aus erreichbar sind.
Performance- und Agilitätsvorteile
Da Beziehungen explizit gespeichert sind, hängt die Abfragegeschwindigkeit von der Länge eines Pfades ab, nicht von der Gesamtgröße des Datensatzes. Selbst bei vielen Millionen Knoten lassen sich mehrstufige Pfade in Millisekunden traversieren.
Gleichzeitig sind Graphmodelle „schemaflexibel“: Neue Entitätstypen oder Beziehungskategorien können ergänzt werden, ohne bestehende Datenstrukturen umzubauen. Diese Agilität ist gerade in dynamischen Cloud- und Hybridumgebungen relevant, in denen sich Abhängigkeiten kontinuierlich verändern.
Abfragesprachen (Cypher, GQL)
Graphabfragen erfolgen über deklarative Sprachen wie Cypher oder standardisiert über die Graph Query Language (GQL nach ISO/IEC 39075:2024).
Diese Sprachen ermöglichen es, Muster zu formulieren – zum Beispiel: „Zeige alle Pfade von extern erreichbaren Systemen zu geschäftskritischen Datenbanken mit maximal fünf Hops.“ Sicherheitsfragen werden damit als Strukturmuster beschrieben, nicht als mehrstufige SQLOperationen.
(open)Cypher ist dabei eine relativ einfach zu erlernende Graph-Abfragesprache, deren visuelle und musterbasierte Syntax es auch Anwendern ohne tiefgehende Programmierkenntnisse ermöglicht, komplexe Beziehungsabfragen präzise zu formulieren (vgl. https://opencypher.org/resources/ und https://neo4j.com/docs/cypher-manual/ sowie Abb. 2).

Abbildung 2: Cypher-Abfrage für musterbasierte Traversierung von Knoten (Actor) und Kanten (ACTED_IN) im Property-GraphModell
Graphtechnologie und KI
Mit künstlicher Intelligenz (KI) löst sich das Sicherheitsdenken weiter von Listen und orientiert sich stärker an der Graph-Logik: Im Bereich der „Graph Data Science“ (GDS) kommen Algorithmen zum Einsatz, die Netzwerkstrukturen systematisch analysieren. Sogenannte Centrality-Verfahren identifizieren einflussreiche Knoten, Community-Detection-Algorithmen erkennen Cluster, Shortest-Path-Analysen machen potenzielle Angriffspfade sichtbar. Diese Verfahren erzeugen Graph-Features: Merkmale, die nicht aus isolierten Attributen, sondern aus der Topologie des Gesamtsystems entstehen und sich direkt in Machine-Learning-(ML)-Modelle integrieren lassen.
Generative KI (GenAI) verschiebt den Fokus weiter von reiner Analyse hin zur kontextbasierten Entscheidungsunterstützung: Graph-Retrieval-Augmented-Generation (GraphRAG) erweitert klassische RAG-Ansätze, die Dokumente aus Vektorindizes abrufen, um die gezielte Traversierung von Knowledge-Graphen. Statt isolierter Textpassagen erhält ein solches Sprachmodell verknüpfte Entitäten, Beziehungen und Abhängigkeiten. Fragen wie „Welche Berechtigungskette führte zu diesem Zugriff?“ lassen sich so entlang realer Beziehungsstrukturen beantworten, ohne komplette Dokumente in das Kontextfenster laden zu müssen. Klassisches GraphRAG folgt dabei einem Push-Prinzip: Relevanter, vorab selektierter Kontext wird in das Modell eingespeist.
Mit Agentic AI geht dieser Ansatz noch einen Schritt weiter: KI-Agenten planen und handeln iterativ, rufen Tools auf und evaluieren Zwischenergebnisse. Dafür benötigen sie dynamischen Zugriff auf Wissensquellen – statt statischem Prompt-Kontext greifen sie bedarfsgesteuert auf den Graphen zu (Pull-Prinzip, vgl. Abb. 3).

Abbildung 3: Bei Graph-RetrievalAugmented-Generation (GraphRAG) liefert ein Prompt kombiniert mit externem Informationsabruf kontextangereicherte Antworten eines Large Language-Models (LLM).
Im diesem Zusammenhang spricht man neuerdings auch von einem Context-Graph. Neben Entitäten und Ereignissen lassen sich damit auch Entscheidungsverläufe modellieren – also beispielsweise, welche Policy, welcher Actor und welches Ereignis im Laufe der Zeit zu welchem Ergebnis geführt haben.
Entscheidungen werden als nachvollziehbare Beziehungsstruktur gespeichert und schaffen einen Wissenslayer über operative Prozesse. Fragen wie „Warum wurde dieses Konto eingefroren?“ oder „Welche Richtlinien führten zu dieser Risikoeinstufung?“ lassen sich so als Traversierung eindeutig herleiten – der Context-Graph wird zum digitalen Gedächtnis einer Organisation. Dieses Gedächtnis dient dabei nicht nur der retrospektiven Nachvollziehbarkeit, sondern auch der prospektiven Entscheidungsfindung. Statt eines reinen Audit-Trails entsteht eine operative Grundlage für zukünftige Entscheidungen.
Security-Repräsentation in Knowledge-Graphen
Graphdatenbanken können ihre operative Wirkung überall dort entfalten, wo komplexe Beziehungen zwischen Entitäten vorliegen – so auch im Sicherheitskontext: Kaum ein anderer Bereich ist so stark von Abhängigkeiten, Pfaden und impliziten Wechselwirkungen geprägt wie moderne IT-Infrastrukturen. Die folgenden Abschnitte zeigen Beispiele, wie sich Knowledge-Graphen in unterschiedlichen Ausprägungen für die InformationsSicherheit nutzen lassen.
Digital Twin: Echtzeit-Abbild der IT-Landschaft
Ein Digital Twin ist im Security-Kontext ein konsistentes, graphbasiertes Abbild der realen IT-Umgebung: Er modelliert Assets, Identitäten, Netzwerkkomponenten, Cloud-Ressourcen, Konfigurationen, Berechtigungen und Sicherheitskontrollen als explizite Knoten mit gerichteten Beziehungen. Jede Entität besitzt definierte Typen und Attribute. Beziehungen beschreiben konkrete technische oder organisatorische Abhängigkeiten wie „ist erreichbar von“, „läuft auf“, „gehört zu Rolle“ oder „ist abgesichert durch“.
Der Aufbau dieses modellierten Wissens erfolgt durch Integration strukturrelevanter Metadaten aus Cloud-APIs, IAM-Systemen, Verzeichnisdiensten, Netzwerk- und Container-Plattformen sowie VulnerabilityScannern. Dabei repliziert man keine Rohlogs, sondern extrahierte Entitäten und Beziehungen, die in ein einheitliches Modell überführt werden – so entsteht ein persistentes Abbild des aktuellen Infrastrukturzustands.
Charakteristisch ist die strukturierte Abbildung von Vertrauenszonen, Segmentierungsgrenzen und systemübergreifenden Abhängigkeiten. Infrastruktur-, Identitäts- und Anwendungsschichten werden dazu in einem gemeinsamen Modell verknüpft und bilden die technische sowie organisatorische Angriffsfläche konsistent ab.
Identity-Graphs: Benutzer, Rollen, Gruppen, Berechtigungen
Ein Identity-Graph modelliert Benutzerkonten, Service-Accounts, Rollen, Gruppen, Policys und deren Beziehungen zu Ressourcen als gerichtete Kanten. Jede Identität wird als eigenständige Entität mit definierten Attributen repräsentiert – etwa Typ, Herkunftssystem oder Authentifizierungsverfahren. Beziehungen bilden direkte und indirekte Rechtezuweisungen ab, beispielsweise „ist Mitglied von“, „hat Rolle“, „darf zugreifen auf“.
Eine solche Datenbasis speist sich typischerweise aus IAM-Systemen, Verzeichnisdiensten, Cloud-Identity-Plattformen sowie applikationsspezifischen Berechtigungsmodellen. Gruppen- und Rollenvererbungen werden nicht implizit angenommen, sondern als transitive Beziehungsketten erstellt. Dadurch entsteht ein durchgängiges Beziehungsmodell effektiver Zugriffsrechte über mehrere Ebenen hinweg.
Ein Identity-Graph führt organisatorische und technische Identitätsstrukturen in einem gemeinsamen Schema zusammen: Identitäten werden systemübergreifend verknüpft und verbinden Rollen-, Policy- und Ressourcenebene in einer einheitlichen Struktur. Auf dieser Grundlage lassen sich privilegierte Identitäten und Rollen identifizieren, die als zentrale Zugriffsknoten (Identity-Chokepoints) weitreichende transitive Zugriffe ermöglichen und ein entsprechend erhöhtes Risiko darstellen.

Abbildung 4: In einer ContextGraph-Architektur arbeiten eine strukturierte Wissensbasis für KI-Modelle, Agenten und dynamische Benutzerinteraktionen zusammen.
Infrastruktur- und Netzwerkgraphen
Ein Infrastruktur- und Netzwerkgraph repräsentiert die physische und logische Struktur einer IT-Umgebung. Im Unterschied zum umfassenderen Digital Twin konzentriert er sich jedoch auf Kommunikationsbeziehungen und systemische Abhängigkeiten, ohne notwendigerweise übergeordnete Kontextinformationen wie Identitäten, Policies oder Sicherheitszustände einzubeziehen.
Knoten umfassen Hosts, virtuelle Maschinen (VMs), Container, Datenbanken, Anwendungs-Schnittstellen (APIs), Load-Balancer, Subnetze oder Netzwerksegmente. Kanten modellieren Kommunikationsbeziehungen, Abhängigkeiten und Zugehörigkeiten – etwa „ist verbunden mit“, „kommuniziert mit“, „ist Teil von Subnetz“ oder „läuft auf Host“.
Die Grundlage sind Metadaten aus CloudAPIs, Netzwerk-Discovery- und Routing-Informationen, Firewall- und Security-Group-Konfigurationen sowie Container-Plattformen. Perimeter-Elemente und Vertrauenszonen werden als eigene Entitäten mit entsprechenden Segmentierungsbeziehungen geführt.
Infrastruktur-, Netzwerk- und Anwendungsschichten werden so in einem einheitlichen Schema zusammengeführt: Das Modell erfasst systemübergreifende Verbindungen und ordnet die technische Topologie der Umgebung konsistent zu. Diese Beziehungen lassen sich als explizite Reachability-Relationen modellieren, etwa in Form von „CAN_REACH“-Beziehungen, die reale Netzwerk- und Zugriffspfade abbilden und die Grundlage für Angriffspfadanalysen bilden.
Vulnerability-Graphs
Viele Tools liefern Listen mit tausenden „Common Vulnerabilities and Exposures“ (CVEs) mit statischen CVSS-Bewertungen – ihnen fehlt jedoch der notwendige Kontext, um zu erkennen, welcher Bruchteil (womöglich nur 1%) davon tatsächlich eine existenzielle Bedrohung für das Unternehmen darstellt.
Ein Vulnerability-Graph ergänzt das Sicherheitsmodell um Schwachstellen, Softwarekomponenten und ihre Abhängigkeiten: CVEs, Versionen, Bibliotheken oder Container-Images werden als eigenständige Entitäten geführt und mit betroffenen Systemen oder Diensten verknüpft. Beziehungen beschreiben etwa „ist betroffen von“, „abhängig von“ oder „läuft mit Version“.
Die Daten stammen aus Vulnerability-Scannern, „Software Bills of Materials“ (SBOMs), Container-Registrys und öffentlichen Datenbanken wie die „National Vulnerability Database“ (https://nvd.nist.gov) oder MITRE ATT&CK (https://attack.mitre.org). Darüber hinaus werden Schwachstelleninformationen mit Infrastruktur- und Anwendungsebene verknüpft, um Schwachstellen kontextbasiert bewerten zu können (Vulnerability-Prioritization-and-Exposure-Management, VPEM).
Eine Reachability-Analysis ermittelt dabei die tatsächliche Erreichbarkeit eines Systems: Die Bewertung des Business-Impacts zeigt an, ob kritische Daten oder Geschäftsprozesse betroffen sind. Zudem sind im Graphen Abhängigkeitsketten zwischen Softwarekomponenten und Systemebenen abgebildet – Bibliotheken, Laufzeitumgebungen und Anwendungen werden als eigenständige Knoten mit ihren Beziehungen erfasst.
In der Risikobewertung fließen technische Kritikalität, tatsächliche Exposition und geschäftliche Auswirkung dann zusammen. Der Vulnerability-Graph macht damit die technische Verwundbarkeit einer Umgebung systematisch analysierbar.
SBOM-Graphen
Ein SBOM-Graph erweitert Vulnerability-Graphen um die strukturierte Abbildung der Softwarelieferkette auf Komponentenebene: Statt nur bekannte Schwachstellen mit Systemen zu verknüpfen, wird die vollständige Zusammensetzung von Anwendungen aus Bibliotheken, Frameworks und Laufzeitabhängigkeiten modelliert. Grundlage sind „Software Bills of Materials“ (SBOMs), die eine versionierte Aufstellung aller enthaltenen Komponenten liefern und auch transitive Abhängigkeiten transparent machen.
Abbildung 5: Beispielhafte Verknüpfung einer Schwachstelle (CVE) mit Applikation, Host-System, Lizenzund Vertragskontext in einem Vulnerability-Graphen

Abbildung 6: Visualisierung eines Angriffspfads in einem SecurityGraphen
Die Datenbasis bilden SBOM-Dokumente in standardisierten Formaten wie OWASP CycloneDX (https://cyclonedx.org) oder das SPDX der Linux-Foundation (https://spdx.dev) – automatisiert erzeugt aus Build-Systemen, Artefakt-Repositorys oder Container-Registries. Nach der Aufnahme (Ingestion) in den Graphen erfolgt die Verknüpfung mit Infrastruktur-, Deployment- und Vulnerability-Daten, wodurch sich Softwarekomponenten eindeutig den Systemen und Umgebungen zuordnen lassen, in denen sie tatsächlich eingesetzt sind. Wird eine neue Schwachstelle bekannt, lassen sich betroffene Anwendungen und Systeme somit unmittelbar identifizieren und Gegenmaßnahmen risikobasiert priorisieren.
Anwendungsfelder in der IT-Sicherheit
Graphbasierte Sicherheitsmodelle entfalten ihren Nutzen nicht allein in der Visualisierung, sondern auch in der operativen Analyse. Tabelle 1 zeigt typische Einsatzszenarien graphbasierter Analysen im Security-Betrieb sowie die jeweils zugrunde liegenden Analyse- und Entscheidungslogiken.
Beispiel-Szenario | Graph-Analyse | Entscheidungslogik | |
Angriffspfadanalyse | Ein extern erreichbares Web- | deterministische Pfad- und | Priorisierung nach tatsächlicher |
Incident Response (laterale | Ein kompromittiertes Benutzerkonto zeigt ungewöhnliche Logins auf mehreren Systemen. Der tatsächliche Ausbreitungsweg ist unklar. | Subgraph-Extraktion von | gezielte Isolation betroffener |
IAM-Härtung | Ein externer Dienstleister | transitive Berechtigungsketten | strukturelle Rechtekonsolidierung, |
Kontextbasierte Vulnerability- | Ein Scanner meldet zahlreiche CVEs mit hohem Score. Ressourcen zur Behebung sind begrenzt. | Bewertung von Schwachstellen | Risikopriorisierung nach realer Angriffslogik statt isolierter CVSS-Werte |
Cloud- und Supply-Chain-Risiken | Eine Drittanbieter-Bibliothek | Traversierung von Softwareabhängigkeiten, | gezielte Isolation oder |
Tabelle 1: Typische Einsatzszenarien graphbasierter Analysen im Security-Betrieb
Die dargestellten Szenarien zeigen, wie aus einem Sicherheitsmodell eine konkrete Entscheidungslogik entsteht: Alle dargestellten Analysen basieren auf strukturierten Pfadabfragen über dem Sicherheitsmodell. Die praktische Einführung eines solchen Security-Graphen verläuft allerdings selten entlang klar abgegrenzter Kategorien: In der Realität greifen Infrastruktur-, Identitätsund Schwachstellendaten ineinander – welche Aspekte im Vordergrund stehen, hängt von Architektur, Reifegrad der Organisation und konkretem Bedrohungsszenario ab.
Implementierung von Security-Graphen
Die Einführung eines Security-Graphen ist kein monolithisches Transformationsprojekt. Sie kann auch iterativ erfolgen: beginnend mit einem klar abgegrenzten Anwendungsfall und in der Folge sukzessive erweitert um zusätzliche Datenquellen und Analysefähigkeiten.
Datenintegration
Der Aufbau startet mit der Integration zentraler Sicherheits- und Infrastrukturquellen wie IAM-Systemen, Konfigurationsdatenbanken, Cloud-APIs, Schwachstellen-Scannern sowie SIEM- oder IDS-Daten.
Entscheidend ist dabei nicht die Replikation aller Rohdaten, sondern die Extraktion strukturrelevanter Entitäten, Beziehungen und Attributen. Ereignisdaten lassen sich selektiv als Beziehungstypen oder Zeitstempel integrieren, um dynamische Analysen zu ermöglichen und deterministische Struktur- und Pfadabfragen im operativen Betrieb sicherzustellen.
Sinnvoll ist es, mit stabilen Strukturdaten zu starten und Eventdaten dynamisch (womöglich auch KI-unterstützt) zu ergänzen.
Graphtechnologie im operativen Security-Einsatz
Die folgenden Beispiele zeigen unterschiedliche sicherheitsrelevante Einsatzszenarien von Neo4j-Kunden – von kontextbasierter Vulnerability-Priorisierung über Infrastruktur- und Angriffspfadtransparenz bis hin zu KI-gestützter Threat-Intelligence-(TI)-Modellierung.
Intuit, ein US-Anbieter für Finanz- und Steuersoftware, integriert Schwachstellen-, Cloud- und Infrastrukturdaten in eine Graphdatenbank, um reale Expositionspfade statt isolierter CVE-Listen zu bewerten. Dabei werden über 500 000 Endpunkte automatisiert zugeordnet. Risiken und Abhängigkeiten lassen sich in Millisekunden analysieren – ein entscheidender Vorteil bei Zero-Day-Szenarien.
JupiterOne, ein in den USA ansässiges Cybersecurity-Start-up im Bereich Cyber-Asset-Attack-SurfaceManagement (CAASM), kombiniert eine graphbasierte Sicherheitsarchitektur mit KI-getriebener Analytik und Automatisierung: Machine-Learning-Modelle und regelbasierte KI-Mechanismen identifizieren komplexe Angriffspfade, bewerten transitive Berechtigungs- und Expositionsketten und unterstützen die automatisierte Priorisierung von Risiken in dynamischen Cloud-Umgebungen.
Der Virtualisierungs-, Netzwerk- und RemoteAccess-Anbieter Citrix modelliert Microservices- und Infrastrukturabhängigkeiten als Beziehungsnetz in einer Graphdatenbank. So lassen sich Transit- und ImpactAnalysen über mehrere Ebenen hinweg durchführen, um sicherheitskritische Verbindungen frühzeitig zu erkennen.
Die Forschungsorganisation MITRE setzt auf Graphtechnologie, um Angriffstechniken wie ihr ATT&CK Framework zu modellieren: Taktiken, Techniken und Gegenmaßnahmen werden verknüpft, sodass sich Bedrohungsmuster systematisch analysieren und mit realen Ereignissen korrelieren lassen.
Neo4j bietet mit seiner Community Edition auch eine Graphdatenbank unter der Open-Source-Lizenz GPLv3 an (https://neo4j.com/product/community-edition/): Der Datenbankkern ist offen zugänglich – ergänzend existieren Enterprise-Funktionen unter kommerzieller Lizenz (Open-Core-Modell).
Modellierungsprinzipien
Ein belastbares Sicherheitsmodell erfordert klare semantische Regeln: eindeutig definierte Entitäts- und Beziehungstypen. Zudem ist zwischen strukturellen (z.B. Netzwerkverbindungen) und kontextuellen Beziehungen (z.B. „verletzte Policy“, „betroffen von CVE“) zu unterscheiden. Diese Trennung erleichtert spätere Analysen und verhindert semantische Vermischung.
Ebenso relevant ist die Zeitdimension: Versionierung oder Zeitstempel ermöglichen es, bei Bedarf historische Zustände zu rekonstruieren und Entwicklungen – etwa eine schleichende Rechteausweitung – sichtbar zu machen.
Zero-Trust-Prüfung
Zero-Trust-(ZT)-Architekturen verlangen verbindliche Authentifizierung und minimale Rechte entlang jeder Verbindung. In einem Graphmodell lassen sich solche Anforderungen als Strukturmuster definieren.
Beispielsweise lässt sich prüfen, ob zwischen zwei Systemen eine Verbindung existiert, ohne dass ein Authentifizierungs- oder Kontrollknoten dazwischengeschaltet ist. Ebenso kann man transitive Zugriffspfade identifizieren, die formell segmentierte Bereiche faktisch wieder verbinden.
Skalierungsstrategien, Echtzeitanforderungen, Betrieb und Governance
Mit wachsender Infrastruktur steigt auch die Größe des Graphen – Skalierbarkeit betrifft dabei nicht nur die Anzahl der Knoten und Beziehungen, sondern vor allem die Frequenz von Aktualisierungen.
Für operative Anwendungsfälle ist zwischen BatchAnalysen (z.B. nächtliche Angriffspfadberechnung) und Near-Real-Time-Updates (z.B. neue Cloud-Ressourcen, Rechteänderungen) zu unterscheiden. Beispielsweise können Streaming-Integrationen Änderungen inkrementell einpflegen, ohne das gesamte Modell neu zu berechnen.
Governance-Aspekte sind ebenfalls zentral: Zugriffskontrolle auf sensitive Graphdaten, Auditierbarkeit von Abfragen und klare Verantwortlichkeiten für Datenqualität sind sorgsam zu definieren und zu überwachen.
Grenzen und Voraussetzungen
Trotz ihrer vielen Vorteile sind Graphdatenbanken nicht zwangsläufig für jedes Szenario die passende Lösung: Ihr Mehrwert entsteht nur, wenn bestimmte technische und organisatorische Voraussetzungen erfüllt sind.
- Zentral ist dabei eine konsistente Datenintegration: nicht die Vielzahl angebundener Quellen entscheidet, sondern die saubere Extraktion strukturrelevanter Entitäten und Beziehungen – unvollständige oder fehlerhafte Daten verzerren Pfadanalysen und Risikobewertungen.
- Ebenso unerlässlich ist Modellierungsdisziplin: Beziehungstypen, Richtungslogiken und Vertrauenszonen müssen eindeutig definiert sein, da eine unscharfe Semantik die Aussagekraft strukturierter Abfragen mindert.
- Schließlich benötigt auch ein Graph kontinuierliche Pflege: Veränderungen in der Infrastruktur, bei Berechtigungen oder Deployments müssen zeitnah abgebildet werden.
- Der Graph ist nicht zuletzt integraler Bestandteil der Sicherheitsarchitektur und verlangt klare Zuständigkeiten zwischen Security-Engineering, Cloud-Teams und Betrieb.
Fazit
Der Einsatz von Graphtechnologie im SecurityManagement verschiebt den Fokus von der reaktiven Ereignisverarbeitung hin zur strukturellen Risikobewertung. Angriffspfade lassen sich berechnen, kritische Knoten identifizieren, Policy-Lücken systematisch erkennen.
In Kombination mit „Graph Data Science“ und generativer KI kann ein adaptives Sicherheitsmodell entstehen, das nicht nur bekannte Muster erkennt, sondern kontextbasiert auch neue Risiken bewertet. KnowledgeGraphen und ein Context-Graph schaffen dabei die Grundlage für erklärbare, nachvollziehbare Entscheidungen – eine zentrale Voraussetzung für Governance, Compliance und Vertrauen in KI-gestützte Systeme.
Der Übergang von Detektion zu Prävention markiert einen entscheidenden Entwicklungsschritt: Statt Angriffe erst nach ihrem Eintritt zu analysieren, lassen sich Schwächen proaktiv identifizieren und (ihre Beseitigung) priorisieren. Graphbasierte Architekturen bilden ein stabiles Fundament für eine Sicherheitsstrategie, die nicht länger in Listen denkt, sondern in Zusammenhängen – und damit der Denkweise moderner Angreifer auf Augenhöhe begegnet.
Konrad Hippius ist Enterprise Executive bei Neo4j – mit fast 20 Jahren Erfahrung in der IT-Branche bringt er umfassendes Know-how in den Bereichen Datenmanagement und Vertrieb mit.