
Dos and Don’ts des Incident-Response
Ein Security-Incident kann jede Organisation treffen. Doch die richtige Vorbereitung und das korrekte Vorgehen entscheiden oftmals darüber, ob der Vorfall lediglich eine relativ harmlose Erfahrung bleibt oder zum veritablen Notfall eskaliert. Unsere Autoren beschreiben, was sich in der Praxis bewährt hat und was nicht.
Kurz nach Arbeitsbeginn wird der IT-Servicedesk mit Anrufen von Mitarbeitern überschwemmt. Die Erstanalyse ergibt, dass hunderte Systeme der Office-IT und einzelne Systeme der Produktions-IT mittels Ransomware verschlüsselt sind und die Anzahl laufend zunimmt. Die Geschäftsleitung entscheidet, nicht auf die Lösegeldforderung einzugehen und dass die IT-Abteilung den Vorfall selbst lösen solle. Diese kappt diverse Netzwerkverbindungen, um eine weitere Ausbreitung der Malware zu verhindern, und versucht, Backups wieder einzuspielen. Währenddessen informiert die Geschäftsleitung die Polizei und den Vorstand. Derweil schicken einzelne Abteilungsleiter ihre Mitarbeiter nach Hause und informieren Kunden und Geschäftspartner nach Gutdünken über die zu erwartenden Verzögerungen. Zu diesem Zeitpunkt erkennt die IT-Abteilung, dass nicht für alle Systeme Backups verfügbar sind.
In den nächsten Stunden und Tagen werden deshalb einige Systeme manuell wieder aufgesetzt. Nach über 16 Stunden im Dauereinsatz müssen die ersten IT-Mitarbeiter ihre Aufgaben aufgrund von Übermüdung unterbrechen und der IT-Leiter engagiert für die Wiederherstellungsarbeiten externe Unterstützung. Drei Tage nach dem Ereignis kann wieder normal gearbeitet und der Vorfall analysiert werden. Weil keine spezifischen Logfiles vorliegen und die betroffenen IT-Systeme neu aufgesetzt wurden, gibt es jedoch keine Spuren mehr. Somit kann man nur vermuten, wie es zur Infektion mit der Ransomware kam.
Aufgrund von Produktionsunterbrechungen, Schadenersatzzahlungen, geforderten Preisnachlässen und der ausgefallenen Arbeitszeit entstand erheblicher Schaden. Glücklicherweise hat das Unternehmen eine Cyberversicherung abgeschlossen. Die Versicherungsgesellschaft weigert sich jedoch, den gesamten entstandenen finanziellen Schaden zu decken, weil sie dem Unternehmen vorwirft, zumindest teilweise fahrlässig gehandelt zu haben.
Was ist wichtig, was nicht?
Der Vorwurf der Versicherungsgesellschaft in unserem Beispiel ist schwer von der Hand zu weisen. Das betroffene Unternehmen war in mehrfacher Hinsicht nicht optimal vorbereitet und hat demzufolge bestenfalls nach bestem Wissen und Gewissen gehandelt. Denn aus Sicht der IT-Abteilung waren alle IT-Systeme gleichwertig. Es war nicht klar, welche Systeme kritischer oder wichtiger als andere waren und sinnvollerweise mit höherer Priorität behandelt werden sollten. Außerdem wurde keine professionelle Datensicherung betrieben.
Damit Unternehmen es bei einem IT-Vorfall besser machen können als im Beispiel, sollte eine Business-Impact-Analyse (BIA) durchgeführt werden, die auch die Grundlage jedes Business-Continuity-Managements (BCM) oder des IT-Service-Continuity-Managements (ITSCM) bilden sollte. Hierbei darf nicht vernachlässigt werden, dass die BIA in erster Linie den Fokus auf die Business-Sicht legt, also welche Prozesse inklusive der benötigten Ressourcen, wie beispielsweise Personal, Informationen/Daten und IT-Systeme, wie lange maximal ausfallen dürfen und wie lange die Prozesswiederherstellung höchstens dauern darf.
Außerdem definiert man in der BIA, welcher maximale Datenverlust toleriert wird. Diese beiden Dimensionen bestimmen üblicherweise, ob IT-Systeme redundant ausgelegt werden, wie lang die Backup-Zyklen sind und welche weiteren Sicherheitsmaßnahmen im Einsatz sind. Aus IT-Sicht darf die Kritikalität einzelner IT-Komponenten wie Netzwerkkomponenten – ohne die ein Großteil der für die Prozesse benötigten Systeme nicht miteinander kommunizieren kann – dabei nicht vernachlässigt werden. Selbstverständlich müssen auch gesetzliche Anforderungen zwingend berücksichtigt werden, zum Beispiel das Datenschutzgesetz, Vorgaben betreffend Revision und steuerliche Auflagen.
Nachdem die BIA vorliegt, können die Verantwortlichen sämtliche IT-Systeme inventarisieren und klassifizieren. Hierbei empfiehlt sich ein ABC-Schema, wobei in Kategorie A sämtliche geschäftskritischen Systeme fallen. Kategorie B umfasst Systeme, welche für die Organisation zwar wichtig sind, deren „nicht-zur-Verfügung-stehen“ aber erst nach einem längeren Zeitraum einen signifikanten Einfluss auf den Betrieb hat. In Kategorie C gehören sämtliche „nice to have“-Systeme. Bei der ABC-Zuordnung sollte man auch bedenken, wie viele Personen von einem Ausfall des einzuordnenden Systems betroffen sind.
Ein Plan muss her
Im Fallbeispiel haben die IT-Mitarbeiter ihr Möglichstes getan, den Normalbetrieb wiederherzustellen. Es war aber nicht klar, ob und welche Personen spezielle Tätigkeiten wahrnehmen sollen und wer in einem Notfall welche Weisungs- und Entscheidungskompetenzen hat. Erschwerend kommt hinzu, dass die Nerven bei einem Security-Incident aufgrund der ungewohnten Situation bei allen Beteiligten blank liegen und der Zeitdruck nicht gerade zur Entschärfung beiträgt.
Deshalb gilt es zu vermeiden, dass sich wichtiges Know-how in der Organisation nur auf wenige Personen verteilt. Denn diese werden bei einem Security-Incident die lange Belastung nicht aushalten, da erfahrungsgemäß die Aufarbeitung des Vorfalls noch länger dauert als der Sicherheitsvorfall selbst.
Damit IT-Abteilungen die Vorfallbehandlung nicht nach dem „Trial and Error“-Prinzip betreiben, sind klare Strukturen unerlässlich. Hilfestellung hierfür bieten diverse Incident-Prozess-Modelle. In Tabelle 1 sind beispielsweise die Incident-Prozessphasen von NIST und SANS einander gegenübergestellt. Aber auch das Bundesamt für Sicherheit in der Informationstechnik (BSI) und die ISO haben entsprechende Prozessmodelle und Normen verfasst.
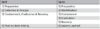
Es spielt allerdings keine Rolle, für welches Modell man sich entscheidet – solange die Vorfallbehandlung nicht als Monolith, sondern als aus verschiedenen Phasen
bestehender Prozess verstanden und systematisch vorgegangen wird. Die Eckpfeiler für ein erfolgreiches Incident-Management sind: Prävention, Erkennung, Behebung
und Verbesserung (siehe auch Abb. 1).

Ohne Checklisten geht nichts
Darüber hinaus macht es wenig Sinn, wenn beispielsweise Applikationsserver wieder online gehen, aber die zugehörigen Datenbanken und Netzwerkverbindungen noch nicht zur Verfügung stehen. Aus Systemsicht gilt es deswegen, die Systemabhängigkeiten zu analysieren und zu dokumentieren. Anschließend wird die Business-Sicht mit den Ergebnissen der BIA und der ABC-Klassifikation eingebracht – und schon ist die Wiederanlaufreihenfolge der gesamten IT-Landschaft definiert, welche die technische Grundlage für den Incident-Response-Prozess bildet.
Im nächsten Schritt sollten Unternehmen verschiedene Anwendungsfälle definieren, zum Beispiel Malware-Pandemie, Datenklau oder Hackerattacke. Danach wird Schritt für Schritt festgelegt, wie im spezifischen Beispiel vorzugehen ist, und in sogenannten „Play Books“ dokumentiert – dabei gibt es nur eins pro Anwendungsfall. Darin sollte beispielsweise stehen:
- Wer macht wann was?
- Wer darf und muss unter welchen Umständen was in welcher Frist entscheiden?
- Dürfen Systeme abgeschaltet oder vom Netz getrennt werden? Unter welchen Voraussetzungen?
- Sollen betroffene Systeme neu aufgesetzt, also möglichst rasch wieder verfügbar auf Kosten der Ursachenerkennung sein (keine IT-forensische Spurensuche mehr möglich) oder müssen immer möglichst alle Spuren erhalten bleiben?
- Wer kommuniziert im Namen der Organisation mit wem?
- Wer entscheidet, ob und wann Dritte zur Lösung hinzugezogen werden sollen?
Je detaillierter diese Checklisten sind, desto verlässlicher sind sie im Ernstfall. Empfehlenswert ist auch die Erarbeitung einer Incident-Response-Kommunikationsstrategie und der zugehörigen Pressemitteilungen, die von der Geschäftsleitung im Voraus genehmigt werden sollten. So gibt es im Ernstfall weniger zu diskutieren, und eine prompte, koordinierte Kommunikation wird von Dritten generell als professionell bewertet.
Weiterhin ist es sehr wichtig, dass alle relevanten Dokumente und Checklisten in Papierform vorliegen, damit sie in jedem Fall bei Bedarf griffbereit sind. Denn was nützen die schönsten Prozessdokumentationen im Intranet, wenn die IT-Infrastruktur aufgrund des eingetretenen Incidents nicht mehr zur Verfügung steht?
Außerdem müssen die rechtlichen Vorgaben eingehalten werden: So fordert die Börsenaufsicht zum Zwecke der Verminderung von Insiderhandel, dass börsennotierte Unternehmen im Fall eines eingetretenen Schadens über den Vorfall informieren müssen, weil dieser einen Einfluss auf den Börsenkurs haben könnte. Laut Datenschutzverordnung muss der Diebstahl von Personendaten zeitnah gemeldet werden. In diesen Fällen macht sich die Organisation bzw. deren Geschäftsleitung strafbar, wenn sie der Informations- und Meldepflicht nicht nachkommt.
Gemeinsam sind wir stark
Kaum ein IT-Mitarbeiter wird in der Lage sein, sämtliche zur Lösung eines IT-Sicherheitsvorfalls nötigen Aufgaben auszuführen. Aus diesem Grund haben sich in der Praxis sogenannte Computer Security Incident Response Teams (CSIRT) bewährt, die aus Spezialisten verschiedener IT-Disziplinen bestehen. Die Experten kennen die IT-Landschaft der Organisation und können sie auf Administratorebene betreuen.
Allerdings wollen und können sich die wenigsten Unternehmen ein dediziertes Vollzeit-CSIRT leisten – vor allem, wenn aufgrund der BIA eine 24/7-Leistungserbringung nötig ist. Deshalb haben viele das Problem so gelöst, dass einige IT-Mitarbeiter ein Doppelberufsleben führen: Im Normalbetrieb gehen sie ihren üblichen IT-Tätigkeiten nach; tritt ein Security-Incident ein, lassen sie alles stehen und liegen und beheben den Vorfall.
Geleitet wird das CSIRT in den meisten Fällen vom Chief (Information) Security Officer – er und sein Stellvertreter sind auch die Schnittstelle zum Management. Eine meistens kostengünstige Option, um das eigene IT-Team mit weiteren Spezialisten zu ergänzen oder Zeiten außerhalb der Regelarbeitszeit abzudecken, ist, einen darauf spezialisierten externen Dienstleister zu beauftragen.
Her mit den Tools
Die IT-Mitarbeiter im Fallbeispiel haben nur aufgrund der Meldungen der Mitarbeiter erkannt, dass ein Security-Incident vorliegt. Wenn ein Monitoring im Einsatz gewesen wäre, dann hätten die Sensoren des Monitoring-Systems Alarm geschlagen – und zwar bevor ein genervter Anwender den IT-Servicedesk kontaktiert hätte.
Alle bisher beschriebenen Maßnahmen sind Teil der Präventionsphase. Dort gehören auch die klassischen Maßnahmen Systemhärtung, Security-Patching und die Ur-Security-Tools Firewall und Anti-Malware-Programme hinein. Ergänzt wird das Arsenal durch Logging, das auf den kritischen Systemen aktiviert wird, und einem entsprechenden Monitoring-Tool, welches bei korrektem Setup und sinnvoller Einstellung den IT-Mitarbeitern die Arbeit abnimmt, sämtliche Logfiles kontinuierlich nach Anomalien zu durchforsten.
Beispiele für Anomalien sind: massiv erhöhte Kommunikation im Netzwerk, Malware-Erkennung, nicht protokollkonforme Datenpakete, erhöhte Anzahl an erfolglosen Login-Versuchen, erhöhte Anzahl an Passwort-Zurücksetzen-Anfragen beim IT-Servicedesk, Zugriffe auf Systeme oder Systemressourcen wie Verzeichnisse oder Datenbanktabellen, auf welche in der Vergangenheit nicht zugegriffen wurde, oder schlicht die Nichtverfügbarkeit von IT-Ressourcen.
Die Kombination eines CSIRT mit entsprechenden Sicherheitstools bildet ein Security-Operations-Center (SOC). Ob eine Organisation ein eigenes SOC aufbaut und betreibt oder diesen Service extern bezieht, hängt primär von den geltenden gesetzlichen Vorgaben, den individuellen Anforderungen und den zur Verfügung stehenden personellen und finanziellen Ressourcen der Organisation ab.
Übung macht den Meister
Wenn das Incident-Response-Management, also das CSIRT, und Die Prozesse definiert, die Checklisten ausgearbeitet und die Tools konfiguriert sind und laufen, dann ist es Zeit für eine Notfallübung oder im Neudeutsch Incident-Response-Exercise (IREX). Erfahrungsgemäß läuft beim ersten Durchlauf so ziemlich alles schief: Die involvierten Mitarbeiter kennen die Prozesse nicht, trauen sich nicht, zeitnah Entscheidungen zu fällen, oder verfallen in Schockstarre. Aus diesem Grund ist es ratsam, den Übungsaufbau vorerst sehr simpel zu halten. Sinnvoll ist beispielsweise, erst einmal einen Walkthrough durch die Incident-Prozesse zu machen und mit jeder erneuten IREX-Durchführung die Komplexität zu erhöhen.
In jedem Fall müssen vorher die Rahmenbedingungen und das Übungsszenario im sogenannten Storybook definiert werden. Ein Beispiel dafür ist: Es soll der Use-Case „Malware-Befall“ geübt werden. Involviert sind die Teams/Abteilungen/Standorte A, B und C. Die Geschäftsleitung und nicht beübte Organisationsbereiche sind darüber informiert, dass eine IREX läuft und sie bei Anfragen von A, B und C an den Übungsleiter verweisen sollen. Die Infizierungen erfolgen mittels fingierten E-Mails, die deutlich als IREX-E-Mails gekennzeichnet sind. Im Storybook steht genau, was um welche Zeit passiert, z. B.:
- Am 10. Oktober 2019, 7:30 Uhr wird Injection 1 ausgelöst; E-Mail von Y an das CSIRT: Meldung Virenbefall von acht Kernsystemen.
- Um 8:15 Uhr wird Injection 2 ausgeführt; E-Mail von Z an das CSIRT: Meldung Virenbefall von zwei Produktionssystemen.
Im Storybook soll auch die inhaltliche und zeitliche Idealreaktion auf die einzelnen Inputs stehen. Um zu verhindern, dass das IREX versandet oder aus der Spur kommt, weil einzelne beübte Stellen nicht, falsch oder viel zu spät reagieren, sollten auch Wiedereinstiegspunkte definiert werden, zum Beispiel „Wir gehen jetzt davon aus, dass A die Geschäftsleitung informiert hat.“ oder „Wir gehen davon aus, dass B die Untersuchung der Malware in Auftrag gegeben hat“. Bei jeder IREX ist es enorm wichtig, dass dokumentiert wird, wer wann was gemacht beziehungsweise veranlasst oder eben unterlassen hat.
Für die meisten Betroffenen ist ein echter Security-Incident eine Extremsituation und es zählt in den meisten Fällen jede Minute. Darum ist es gut zu wissen, dass sich das CSIRT auf in diversen Übungen bewährte Prozesse, Checklisten und IT-Tools verlassen kann. So bleibt zudem die Zahl von nicht berücksichtigten Ad-hoc-Entscheidungen und -Aktivitäten überschaubar und das wiederum verringert potenzielle Risiken und tatsächliche Schäden signifikant.
Wie konnte es nur dazu kommen?
Um zu verhindern, dass ein Vorfall kurz nach seiner Behebung erneut auftritt, beispielsweise durch abermaliges Anklicken eines mit Malware verseuchten E-Mail-Anhangs, sollte die Ursache untersucht werden – im Idealfall von unabhängigen Spezialisten. Auch wenn aufgrund erster Handlungen wie im obigen Beispiel keine stichfeste Aussage über den genauen Hergang gemacht werden kann, wird so ein erneutes Auftreten verhindert.
In jedem Fall sollten zu diesem Zeitpunkt bekannte Sicherheitslücken umgehend durch das Einspielen von Sicherheitspatches, das Einführen neuer Sicherheitsmechanismen und Sicherheitsmaßnahmen geschlossen und potenzielle Schadsoftware aus allen Quellen gelöscht werden, bevor man zum Normalbetrieb zurückkehrt. Denn Informationen über erfolgreiche Angriffe können nicht nur den Medien entnommen werden, sondern Angreifer teilen sie auch im Darknet. So ist es möglich, dass Nachahmungstäter auftauchen und die Angriffe wiederholen oder sich an eine laufende Attacke dranhängen.
Wissen ist Macht
Nach jeder IREX und jedem Security-Incident hat die Organisation die Chance, den Vorfall und die Vorfallsbehandlung des Unternehmens zu analysieren, um sich kontinuierlich zu verbessern. Wenn sich das Unternehmen im Fallbeispiel an diesen Grundsatz gehalten hätte, dann wäre die Schadenssumme nur ein Bruchteil gewesen.
Wird eine Attacke der Öffentlichkeit bekannt, sollte der Sicherheitsverantwortliche prüfen, ob dieselbe oder eine ähnliche Attacke auch in der eigenen Organisation eintreten könnte. Die notwendigen Mittel dazu sollten ihm zur Verfügung gestellt werden, seien es interne oder externe Ressourcen. So lässt sich beispielsweise die Ausbreitung einer großen Angriffswelle verhindern.
Christoph Baumgartner und Tobias Ellenberger verfügen über langjährige Beratungserfahrung und leiten die auf Cyber-Security-Consulting, DFIR und Penetration Test / Red Teaming spezialisierte Oneconsult Unternehmensgruppe (www.oneconsult.de) mit Büros in Deutschland und der Schweiz.