
Alles ist relativ : Anonymisierungstechniken im Realitätscheck
Spätestens seit Daten als das neue Gold im virtuellen Raum gelten, haben sich Spannungen um eine datenschutzkonforme Nutzung und damit auch die Bewertung von Pseudonymisierung oder Anonymisierung verschärft – Protokolldaten für Security-Maßnahmen sowie Anwendungen der künstlichen Intelligenz befeuern diese Debatte ebenfalls. Der vorliegende Beitrag erörtert Methoden zur Entpersonalisierung personenbezogener Daten und liefert eine Einordnung in die Praxis der Aufsichtsbehörden sowie relevante Urteile des Europäischen Gerichtshofs.
Die Bundesbeauftragte für den Datenschutz und die Informationsfreiheit (BfDI) hat im Sommer 2025 ein Konsultationsverfahren zum datenschutzkonformen Umgang mit personenbezogenen Daten in Modellen der künstlichen Intelligenz (KI) durchgeführt. Die rege Beteiligung am Konsultationsverfahren war dabei nicht nur der Aktualität des Themas KI geschuldet: „Mit Berichten über Falschaussagen in LLMs über reale Personen oder die Ausgabe von personenbezogenen Daten sowie Ankündigungen, Nutzerinhalte wie Bilder oder öffentliche Chatverläufe als Trainingsdaten zu verwenden, wird die Frage aufgeworfen, wie es sich mit dem Schutz personenbezogener Daten in der Memorisierung und in der Ausgabe beim sogenannten Prompting verhält“, begründete etwa die Gesellschaft für Informatik e.V. (GI) ihre Befassung mit den Fragestellungen der BfDI in ihrer Stellungnahme vom 11. August 2025 [1]: „Neben der Verwendung von personenbezogenen Daten als Trainingsdaten stehen für eine datenschutzkonforme Verwendung von KI-Modellen noch weitere Aspekte im Raum, die Beachtung finden müssen. So bergen beispielsweise LLMs das Risiko der De-Anonymisierung, insbesondere für kleine und marginalisierte Gruppen […].“
Gesellschaftliche Aspekte der Anonymisierung beziehungsweise De-Anonymisierung und ihre Folgen für die Nutzer* stehen dabei im Kontext von LLMs und KI nicht zum ersten Mal im Fokus – häufig stehen sie auch im Widerspruch zu wirtschaftlichen Interessen der IT- oder KI-Hersteller und -Dienstleister. Die Ursachen hierfür sind unter anderem in der binären Logik der Datenschutz-Grundverordnung (DSGVO) zu finden, die offenbar Spielräume für unterschiedliche Auslegungen eröffnet und zugleich zu praktischen – sowohl technischen als auch organisatorischen – Herausforderungen in der Anwendung führen kann: Die DSGVO operiert formal binär in dem Sinne, dass sie nur dann anwendbar ist, wenn es sich bei den Daten um „personenbezogene Daten“ handelt – und bei nicht-personenbezogenen Daten eben nicht.
Dieser Binarität stehen in der Realität datengetriebener Systeme jedoch Graustufen gegenüber, in denen Daten graduell zwischen „klar personenbezogen“ und „klar anonym“ liegen. Gerade bei de-personalisierten Daten – ob nun im Zuge einer Anonymisierung oder Pseudonymisierung – entsteht ein Graubereich, der juristisch relevant ist. Denn davon, ob de-personalisierte Daten nach der Anwendung entsprechender Verfahren weiterhin als personenbezogene oder eben als nicht-personenbezogene Daten zu qualifizieren sind, hängt für Hersteller und Dienstleister die Anwendbarkeit der DSGVO ab – einschließlich der Berücksichtigung der daraus resultierenden Vorgaben in ihren Produkten.
Die DSGVO wird dem durch einen relativen Definitionsansatz gerecht: Ist eine Re-Identifikation durch eine gegebene Partei (und ausgehend von deren Fähigkeiten etc.) nicht „nach allgemeinem Ermessen wahrscheinlich“, so gelten die Daten für diese Partei als nicht personenbezogen (vgl. Erwägungsgrund 26 der DSGVO, siehe etwa https://dsgvo-gesetz.de/erwaegungsgruende/nr-26/).
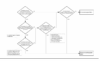
Abbildung 1: Bestimmung der Personenbezogenheit von Daten im Sinne der DSGVO (vgl. [3])
Anforderungen im Wandel
Jörg Pohle und Julian Hölzel haben diesen Punkt bereits in der BfDI-Konsultation zur Anonymisierung aufgegriffen [2]: Wird das gewählte Anonymisierungsverfahren als hinreichend dafür angesehen, dass der Output als nicht-personenbezogenes Datum gilt, ist dieser nicht mehr von der DSGVO erfasst. Anonymisierung stellt für die Autoren damit eine Möglichkeit der legalen Flucht aus dem Datenschutzrecht dar, die inzwischen von immer mehr öffentlichen und privaten Stellen genutzt werde. Dies umfasse auch gerade „solche Global Players, denen der Schutz ihrer Nutzerinnen und Nutzer sonst explizit gleichgültig ist“.
Im vorliegenden Beitrag werden zunächst die Begriffe im Hinblick auf die aktuellen Quellen und Vorgaben eingegrenzt sowie zwei konkurrierende Konzepte zur praktischen – technischen und/oder organisatorischen – Umsetzung der Vorgaben aus der DSGVO vorgestellt. Welche Implikationen haben diese Konzepte für die Bewertung der „Wirksamkeit“ technischer Lösungen und Maßnahmen? Hierzu diskutieren die folgenden Abschnitte Konzepte von „Anonymitätsgarantien“ und skizzieren klassische Anonymisierungstechniken im Kontext.
Abschließend geht es darum, welche Anforderungen unter Berücksichtigung des Stands der Wissenschaft sinnvoll erscheinen – auch im Lichte einer aktuellen Entscheidung des Europäischen Gerichtshofs (EuGH), die mit einer weiteren neuen Interpretation und zusätzlichen Anforderungen aufwartet. Dem vorliegenden Artikel fachlich zugrunde liegende Quellen sind allem voran das Paper „They who must not be identified – distinguishing personal from non-personal data under the GDPR“ von Michele Finck und Frank Pallas [3] sowie der Bericht zum 7. PET-Talk mit Maike Kamp: Anonymisierung und Pseudonymisierung [4].
Begriffsbestimmung
Anonymisierung und Pseudonymisierung sind aus Sicht der DSGVO durchaus geregelt, werden aber häufig missverstanden. Die DSGVO ordnet pseudonymisierte Daten ausdrücklich als personenbezogene Daten ein. Erwägungsgrund 26 „Keine Anwendung auf anonymisierte Daten“ (ErwG 26) stellt klar: Daten, die pseudonymisiert wurden und sich mithilfe von Zusatzinformationen wieder einer Person zuordnen lassen, gelten weiterhin als personenbezogen. Entscheidend ist dabei, dass Pseudonymisierung kein Weg sein soll, dem Geltungsbereich der DSGVO zu entfliehen, sondern ein Instrument zur Risikominderung innerhalb der DSGVO darstellt. Die Existenz eines „Schlüssels“ oder zusätzlicher Informationen genügt, um den Personenbezug wiederherzustellen. Pseudonymisierung wird gelegentlich fälschlich als „fast anonym“ interpretiert, während sie tatsächlich das Gegenteil bedeutet: explizit regulierte Personenbezogenheit.
Anonymisierte Daten sind nach ErwG 26 solche, bei denen die betroffene Person nicht oder nicht mehr identifizierbar ist. Maßgeblich ist dabei jedoch nicht die absolute Unmöglichkeit der Identifizierung, sondern – sinngemäß – die Frage, ob „alle Mittel […], die von dem Verantwortlichen oder einer anderen Person nach allgemeinem Ermessen wahrscheinlich [zur Re-Identifikation] genutzt werden“, ausgeschlossen sind. Zu beachten ist hierbei, dass die Bewertung für verschiedene (z.B. über abweichende Zusatzinformationen verfügende) Akteure unterschiedlich ausfallen kann: Ein und dasselbe Datum kann so für Akteur A als personenbezogen, für Akteur B aber als nichtpersonenbezogen gelten (sog. „relativer Ansatz“, vgl. [3,5]).
Pohle und Hölzel wiesen in ihrer Stellungnahme zum BfDI-Konsultationsverfahren zur Anonymisierung [2] auf einen weiteren zentralen Aspekt hin: Anonyme Daten dürfen nicht mit anonymisierten Daten gleichgesetzt werden. Eine Anonymisierung personenbezogener Daten erzeugt keine „anonymen“ Daten, sondern „anonymisierte Daten“. Die Verwendung des Begriffs „anonyme Daten“ würde demgegenüber implizieren, dass diese Daten bereits zum Zeitpunkt ihrer Erhebung oder Sammlung nicht personenbezogen waren. Solche tatsächlich anonymen Daten kommen in der Praxis jedoch mittlerweile nur selten vor, da es kaum noch Möglichkeiten zur Nutzung digitaler Angebote ohne eindeutige Identifizierung gibt (künftig vermutlich auch ohne Altersverifikation) und darüber hinaus vielfältige Risiken zur anderweitigen Re-Identifikation bestehen – beispielsweise durch Verschränkung unterschiedlicher Datensätze.
Konkurrierende Konzepte
Für die – technische und/oder organisatorische – Umsetzung der Anonymisierung sind zwei offenbar gegensätzliche Vorgaben relevant. Im Verständnis der DSGVO (ErwG 26) ist Anonymität relativ: Ein Restrisiko ist zulässig und die Bewertung erfolgt nach einem Abwägungsmaßstab, der Kosten, Zeitaufwand, den Stand der Technik sowie realistische Angriffe berücksichtigt und zudem für verschiedene Akteure zu unterschiedlichen Bewertungsergebnissen kommen kann. „Bei der Feststellung, ob Mittel nach allgemeinem Ermessen wahrscheinlich zur Identifizierung der natürlichen Person genutzt werden, sollten alle objektiven Faktoren, wie die Kosten der Identifizierung und der dafür erforderliche Zeitaufwand, herangezogen werden, wobei die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologische Entwicklungen zu berücksichtigen sind“, so der Wortlaut.
Im ErwG 26 DSGVO wird Anonymität damit nicht als absoluter Zustand definiert, sondern über einen Wahrscheinlichkeitsmaßstab. Entscheidend im Sinne der DSGVO ist die sogenannte Reasonable Likelihood, also die Wahrscheinlichkeit „nach allgemeinem Ermessen“ – das heißt: Zur Bestimmung, ob eine Person identifizierbar ist, sind alle Mittel zu berücksichtigen, die vernünftigerweise wahrscheinlich zur Identifizierung genutzt werden (könnten).
Reasonable Likelihood im Sinne des ErwG 26 ist kein mathematischer, sondern ein rechtlich-normativer Begriff, der in zwei Dimensionen relativ ist:
- relativ zum Angreifer: Wer versucht zu re-identifizieren? Mit welchen Ressourcen, Technologien, Fähigkeiten und Motivationen handelt er?
- relativ zur Zeit: Denn was heute unverhältnismäßig ist, kann morgen trivial sein – technischer Fortschritt muss daher mit berücksichtigt werden.
Anonymität ist damit – ähnlich übrigens wie Sicherheit – kein absoluter Zustand, sondern eher eine Momentaufnahme unter Annahmen. Besonders wichtig, in technischen Debatten jedoch häufig unbeachtet ist dabei, dass das Konzept der Reasonable Likelihood von der bloßen theoretischen Möglichkeit der Re-Identifizierbarkeit zu unterscheiden ist! Es genügt nicht, dass eine Re-Identifizierung denkbar oder logisch möglich ist – entscheidend ist vielmehr, ob ihre tatsächliche Durchführung durch einen bestimmten Akteur praktisch erwartbar ist.
In der Aufsichtslogik, konkret in der Handreichung der Artikel-29-Datenschutzgruppe (Article 29 Working Party [6], seit 2018: Europäischer Datenschutzausschuss, EDPB), wurde hingegen die Forderung verankert, dass Anonymität irreversibel sein müsse und keine verbleibende Identifizierbarkeit zulässig sei. Das implizite Fazit lautet: Anonymisierung soll faktisch so endgültig – oder absolut – sein wie die Löschung von Daten. Zwar folgt diese Logik nicht explizit aus der DSGVO, sie wurde jedoch zum De-facto-Standard.
Die Handreichung führte damit zu einer Verschiebung des Maßstabs in der Aufsichtspraxis: Während ErwG 26 DSGVO eine Risikoabwägung verlangt und ausdrücklich auf das Kriterium „nach allgemeinem Ermessen wahrscheinlich“ abstellt, interpretieren die Aufsichtsbehörden diesen Maßstab faktisch häufig als einen nahezu Null-Risiko-Standard mit impliziter Forderung nach Irreversibilität. Anstelle einer Bewertung von Lösungsansätzen oder Techniken zur Anonymisierung anhand risikobasierter Kriterien wird implizit eine „absolute Anonymität“ eingefordert.
Absolute Anonymität als Kategorienfehler
Diese Forderung steht offensichtlich in einem Spannungsverhältnis zum Konzept der Reasonable Likelihood: Während absolute Anonymität den Ausschluss jedes Restrisikos impliziert, akzeptiert Letztere durchaus Restrisiken, solange diese nicht „nach allgemeinem Ermessen wahrscheinlich“ sind.
- Die Forderung nach absoluter Anonymität kann dabei wenig überzeugen: Erstens sind absolute Forderungen auch im Bereich der IT-Sicherheit unüblich und technisch unrealistisch: Kryptografische Verfahren etwa gewährleisten keine absolute Vertraulichkeit, sondern beruhen auf Annahmen, nach denen sie nach dem aktuellen Stand der Wissenschaft für einen bestimmten, zeitlich begrenzten Zeitraum nicht gebrochen werden können (vgl. etwa die BSI-Empfehlungen zu Schlüssellängen [7]).
- Zweitens entsprechen absolute Forderungen weder dem Wortlaut von ErwG 26 DSGVO noch dem dahinterstehenden Ziel des Gesetzgebers.
- Drittens ist absolute Anonymität technisch in vielen Fällen gar nicht umsetzbar, weil sich bestimmte Re-Identifikationsrisiken beispielsweise sogar für stark generalisierte oder aggregierte Daten ergeben.
- Nicht zuletzt würden, viertens, Forderungen zur absoluten Anonymität potenziell auch die Fortentwicklung und tatsächliche Anwendung datenschutzfreundlicher Technologie und Praktiken (z.B. zum sog. Privacy-Preserving Learning) behindern.
Denn datenschutzfreundliche Techniken folgen in vielen Fällen naturgemäß und gezwungenermaßen einem risiko- und wahrscheinlichkeitsbasierten Ansatz: Würden solche Verfahren in einem absoluten Verständnis keinen „Nutzbarkeitsvorteil“ gegenüber dem bisherigen Vorgehen liefern, bestünde auch kein Anreiz zu ihrer tatsächlichen Anwendung. Unternehmen würden vielmehr weiterhin versuchen, die Verarbeitung ohnehin als personenbezogen geltender Daten über fragwürdige Vorgehensweisen zu legitimieren und sich zusätzlichen Aufwand für datenschutzfreundliche Technologie sparen.
Reasonable Likelihood verlangt daher kein perfektes Verfahren, sondern transparente Annahmen, klar definierte Angreifermodelle sowie nachvollziehbare Risikoabwägungen. Die Frage nach belastbaren Techniken zur Anonymisierung ist folglich weniger, ob eine Re-Identifizierung „irgendwie möglich“ ist, sondern ob sie unter realistischen Bedingungen tatsächlich zu erwarten ist.
Formale Anonymitätsgarantien
Ein in der technisch-rechtlichen Debatte noch vergleichsweise wenig präsentes, für die technische Abbildung der Reasonable Likelihood sowie deren (aufsichts-) rechtliche Diskussion aber ausgesprochen hilfreiches Konzept besteht in formal definierten Anonymitätsmaßen, deren Erfüllung sich in technischen Verfahren garantieren lässt.
Bekannte Beispiele für solche formalen Anonymitätsgarantien sind etwa k-Anonymity, l-Diversity, t‑Closeness oder eine Vielzahl unterschiedlich gelagerter Konzepte der sogenannten Differential Privacy (DP). Verfahren der „klassischen“ Anonymisierung beruhen dabei meist auf Generalisierung (z.B. Altersgruppen), Suppression (Entfernung seltener Merkmale) oder Annahmen über begrenztes Zusatzwissen. Im Fall von k-Anonymity werden Daten hingegen beispielsweise so verändert (etwa durch Generalisierung), dass jede Person in einer Gruppe von mindestens k nicht unterscheidbaren Personen verborgen ist. Bei l-Diversity beziehungsweise t-Closeness werden Erweiterungen eingesetzt, um Attributinferenz zu erschweren. Je nach Datensatz, Anwendungsfall und zu betrachtendem Akteur können diese Garantien – bei ausreichend gewähltem Faktor für k, l und t – durchaus ausreichen, um eine Re-Identifikation „reasonably unlikely“ erscheinen zu lassen.
In Fällen, bei denen große Mengen relevanten Zusatzwissens realistisch verfügbar und kombinatorisch nutzbar sind sowie dynamische Datensätze weitere Angriffsvektoren eröffnen, kommt das Konzept der Differential Privacy (DP) ins Spiel: DP garantiert, dass das Ergebnis einer Analyse nahezu gleich bleibt, unabhängig davon, ob ein bestimmter Datensatz (eine Person) enthalten ist oder nicht. Technisch erreicht man das durch das kontrollierte Hinzufügen von „Rauschen“ – parametrisiert über ε (sog. Datenschutzbudget: je niedriger ε, desto mehr „Rauschen“ wird hinzugefügt) sowie gegebenenfalls weitere Parameter.
Allen Ansätzen gemein ist, dass sich die gewährleisteten Garantien je nach Einzelfall und zu erreichender „Likelihood“ parametrisieren lassen: Sowohl Verfahren der k-/l-/t-Familie wie auch DP können damit realistische Antworten auf das Kriterium der Reasonable Likelihood liefern, da nicht Unmöglichkeit, sondern eine explizite Begrenzung des Risikos mit formalen Garantien versprochen wird.
Verfahren mit Anonymitätsgarantien ermöglichen somit ein formales Risikomodell und machen Schutzwirkungen quantifizierbar. In der regulatorischen/aufsichtsbehördlichen Praxis ließe sich auf dieser Grundlage beispielsweise diskutieren, welche Werte in einem gegebenen Einzelfall als angemessen anzusehen wären.
Angesichts der Spannung zwischen den Vorgaben des ErwG 26 DSGVO und der Handreichung der Artikel-29-Datenschutzgruppe erscheint ein Umdenken in der bisher statuierten Position der Datenschutzaufsichtsbehörden geboten. Dies gilt umso mehr, weil gängige technische Lösungen ohnehin keine absolute Anonymität gewährleisten, sondern häufig lediglich Wahrscheinlichkeiten technisch strukturieren und abbilden können. Die bestehende Diskrepanz resultiert dabei, wie bereits angespochen, weniger aus dem Normtext selbst als vielmehr aus aufsichtsbehördlichen Leitlinien, Prüfpraktiken sowie einem impliziten Null-Risiko-Narrativ.
Erforderliches Umdenken
Mögliche Empfehlungen beginnen bei einer Abkehr vom Denken in absoluten Kategorien, das auch im Kontext der Informationssicherheit unüblich ist: Technische Verfahren arbeiten naturgemäß mit Wahrscheinlichkeiten, Annahmen und definierten Bedrohungsszenarien, die sich für unterschiedliche Akteure unterschiedlich darstellen können. Übertragen auf den Datenschutz würde dies – ähnlich wie im Bereich der Informationssicherheit – bedeuten, dass explizite Angreifermodelle zugelassen, dokumentierte Annahmen bewertet und quantitative Risikogrenzen akzeptiert werden, während man eventuell verbleibende Restrisiken quantifizieren, begründen, begrenzen und fortlaufend überwachen müsste.
Auch der Risikoansatz selbst würde eine stärkere Konkretisierung vertragen, etwa durch eine Abkehr von universellen Kriterien hin zu situativen Bewertungen von Anonymität: Anstatt Anonymität also losgelöst von Zweck, Datenumgebung, Zugriffsszenarien oder Governance-Strukturen zu beurteilen, sollte sie einzelfallbezogen bewertet werden. Dieselbe Technik oder dasselbe Anonymitätsmaß kann in einem Forschungskontext ausreichend, in einem offenen Datenmarktplatz hingegen unzureichend sein.
Verfahren wie Differential Privacy sind dabei nicht deshalb überlegen, weil sie „besonders stark anonymisieren“, sondern weil sie Risiken formal beschreibbar, bewertbar und anwendungsfallspezifisch verlässlich parametrisierbar machen.
Ausblick
Das jüngste EuGH-Urteil zur Anonymisierung von Daten (SRB-Urteil [8]) hat im September 2025 weitere neue Wege aufgezeigt und zusätzliche Möglichkeiten der Regulierung eröffnet. Im Mittelpunkt standen dabei Fragen der juristischen Definition identifizierter und identifizierbarer Personen, die Bedeutung kontextspezifischer Faktoren bei möglichen Re-Identifizierungen sowie Kriterien für die Beurteilung von Anonymität.
Im 7. PET-Talk der Fachgruppe „Privacy Enhancing Technologies“ (PET) der GI [4] gab Meike Kamp, die Berliner Beauftragte für Datenschutz und Informationsfreiheit sowie Vorsitzende der Datenschutzkonferenz 2025 (DSK), einen Überblick über den aktuellen Stand und die Fortschritte der europäischen Leitlinien zu Anonymisierung und Pseudonymisierung – und nicht zuletzt darüber, wie sich deren inhaltliche Ausgestaltung durch das genannte Urteil verändert. Aus einem Rechtsstreit zwischen dem Europäischen Datenschutzbeauftragten (EDSB) und dem „Einheitlichen Abwicklungsausschuss“ (SRB) heraus hat der EuGH die Bedeutung des Begriffs der personenbezogenen Daten bei der Übermittlung pseudonymisierter Daten an Dritte präzisiert: Der EuGH stellte klar, dass pseudonymisierte Daten nicht in jedem Fall und für jede empfangende Stelle als personenbezogene Daten anzusehen sind – maßgeblich für die Beurteilung der Identifizierbarkeit sei vielmehr der konkrete Kontext der jeweiligen Datenverarbeitung im Einzelfall.
Aufbauend auf aktualisierten europäischen Leitlinien, deren finale Fassung für das Frühjahr 2026 erwartet wird, plant die DSK ein Operationalisierungspapier mit praktischen Beispielen und praxisnahen Erläuterungen zu Anforderungen und Verfahren der Anonymisierung und Pseudonymisierung. Ziel ist es, Verantwortlichen kontextspezifische Verfahren zur Datenverarbeitung an die Hand zu geben, die den Stand von Wissenschaft und Forschung angemessen berücksichtigen. Ein zentrales Thema war dabei die Frage nach den Kriterien, die den Einsatz von PETs zur Gewährleistung von Anonymität oder zum Schutz pseudonymer Daten erfordern – im Einzelfall ist dabei auch der Aufwand für den Einsatz von PETs wie etwa Differential Privacy, k-Anonymität oder l-Diversität zu erwägen. Auf das angekündigte Operationalisierungspapier, das praxisnahe Abwägungsbeispiele in Aussicht stellt, darf man daher mit Spannung blicken – die wird hierüber zu gegebener Zeit berichten.
Prof. Dr. Frank Pallas ist Professor für Privacy Engineering and Policy-Aligned Systems (PEPSys) an der Paris Lodron University of Salzburg (PLUS) sowie unter anderem Sprecher der Fachgruppe „Datenschutzfördernde Technik (Privacy-Enhancing Technologies, PETs)“ der GI e.V.
Dr. Aleksandra Sowa ist zertifizierte Datenschutzbeauftragte, Datenschutzauditorin und IT-Compliance-Manager, Sachverständige für IT-Sicherheit sowie Mitglied im Leitungskreis der GI-FG „PETs“.
Literatur
[1] Gesellschaft für Informatik (GI) e.V., Stellungnahme der GI zur Konsultation der BfDI zum datenschutzkonformen Umgang mit personenbezogenen Daten in KI-Modellen, August 2025, https://gi.de/fileadmin/GI/Positionen/2025-08-12_GI_Stellungnahme_BfDI_Konsultation_Umgang_mit_personenbezogenen_Daten_in_KI-Modellen_fnl.pdf
[2] Jörg Pohle, Julian Hölzel, Anonymisierung aus Sicht des Datenschutzes und des Datenschutzrechts, März 2020, https://www.hiig.de/wp-content/uploads/2020/03/2020-Pohle-H%C3%B6lzel-Anonymisierung-aus-Sicht-des-Datenschutzes-und-desDatenschutzrechts.pdf
[3] Michèle Finck, Frank Pallas, They who must not be identified — distinguishing personal from non-personal data under the GDPR. International Data Privacy Law, Vol. 10 No. 1, S. 11, März 2020. online verfügbar unter https://academic.oup.com/idpl/article/10/1/11/5802594
[4] Gesellschaft für Informatik (GI) e.V. – Fachgruppe Privacy Enhancing Technologies (PET), 7. PET-Talk – Anonymisierung und Pseudonymisierung, Bericht, Oktober 2025, https://fg-pet.gi.de/mitteilung/bericht7-pet-talk-anonymisierung-und-pseudonymisierung
[5] Europäische Union, Urteil des Gerichtshofs (Zweite Kammer) … in der Rechtssache C-582/14 … Patrick Breyer gegen Bundesrepublik Deutschland …, Oktober 2016, https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=ecli:ECLI:EU:C:2016:779
[6] EU Artikel 29 Working Party, Opinion 4/2007 on the concept of personal data, 01248/07/EN WP 136, Juni 2007, https://ec.europa.eu/justice/article-29/documentation/opinion-recommendation/files/2007/wp136_en.pdf
[7] Bundesamt für Sicherheit in der Informationstechnik (BSI), Kryptographische Verfahren: Empfehlungen und Schlüssellängen, BSI TR-02102, Januar 2025, www.bsi.bund.de/dok/TR-02102
[8] Europäische Union, Urteil des Gerichtshofs (Erste Kammer) … in der Rechtssache C-413/23 P … Europäischer Datenschutzbeauftragter (EDSB) … gegen Einheitlicher Abwicklungsausschuss (SRB) …, September 2025, https://eur-lex.europa.eu/legal-content/DE/TXT/?uri=ecli:ECLI:EU:C:2025:645